1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
|
import struct
from typing import List
class SimpleSM4Cipher:
SM4_FK = [0xa3b1bac6, 0x56aa3350, 0x677d9197, 0xb27022dc]
SM4_CK = [
0x00070e15, 0x1c232a31, 0x383f464d, 0x545b6269,
0x70777e85, 0x8c939aa1, 0xa8afb6bd, 0xc4cbd2d9,
0xe0e7eef5, 0xfc030a11, 0x181f262d, 0x343b4249,
0x50575e65, 0x6c737a81, 0x888f969d, 0xa4abb2b9,
0xc0c7ced5, 0xdce3eaf1, 0xf8ff060d, 0x141b2229,
0x30373e45, 0x4c535a61, 0x686f767d, 0x848b9299,
0xa0a7aeb5, 0xbcc3cad1, 0xd8dfe6ed, 0xf4fb0209,
0x10171e25, 0x2c333a41, 0x484f565d, 0x646b7279
]
SM4_SBOX = [
0xd6, 0x90, 0xe9, 0xfe, 0xcc, 0xe1, 0x3d, 0xb7, 0x16, 0xb6, 0x14, 0xc2, 0x28, 0xfb, 0x2c, 0x05,
0x2b, 0x67, 0x9a, 0x76, 0x2a, 0xbe, 0x04, 0xc3, 0xaa, 0x44, 0x13, 0x26, 0x49, 0x86, 0x06, 0x99,
0x9c, 0x42, 0x50, 0xf4, 0x91, 0xef, 0x98, 0x7a, 0x33, 0x54, 0x0b, 0x43, 0xed, 0xcf, 0xac, 0x62,
0xe4, 0xb3, 0x1c, 0xa9, 0xc9, 0x08, 0xe8, 0x95, 0x80, 0xdf, 0x94, 0xfa, 0x75, 0x8f, 0x3f, 0xa6,
0x47, 0x07, 0xa7, 0xfc, 0xf3, 0x73, 0x17, 0xba, 0x83, 0x59, 0x3c, 0x19, 0xe6, 0x85, 0x4f, 0xa8,
0x68, 0x6b, 0x81, 0xb2, 0x71, 0x64, 0xda, 0x8b, 0xf8, 0xeb, 0x0f, 0x4b, 0x70, 0x56, 0x9d, 0x35,
0x1e, 0x24, 0x0e, 0x5e, 0x63, 0x58, 0xd1, 0xa2, 0x25, 0x22, 0x7c, 0x3b, 0x01, 0x21, 0x78, 0x87,
0xd4, 0x00, 0x46, 0x57, 0x9f, 0xd3, 0x27, 0x52, 0x4c, 0x36, 0x02, 0xe7, 0xa0, 0xc4, 0xc8, 0x9e,
0xea, 0xbf, 0x8a, 0xd2, 0x40, 0xc7, 0x38, 0xb5, 0xa3, 0xf7, 0xf2, 0xce, 0xf9, 0x61, 0x15, 0xa1,
0xe0, 0xae, 0x5d, 0xa4, 0x9b, 0x34, 0x1a, 0x55, 0xad, 0x93, 0x32, 0x30, 0xf5, 0x8c, 0xb1, 0xe3,
0x1d, 0xf6, 0xe2, 0x2e, 0x82, 0x66, 0xca, 0x60, 0xc0, 0x29, 0x23, 0xab, 0x0d, 0x53, 0x4e, 0x6f,
0xd5, 0xdb, 0x37, 0x45, 0xde, 0xfd, 0x8e, 0x2f, 0x03, 0xff, 0x6a, 0x72, 0x6d, 0x6c, 0x5b, 0x51,
0x8d, 0x1b, 0xaf, 0x92, 0xbb, 0xdd, 0xbc, 0x7f, 0x11, 0xd9, 0x5c, 0x41, 0x1f, 0x10, 0x5a, 0xd8,
0x0a, 0xc1, 0x31, 0x88, 0xa5, 0xcd, 0x7b, 0xbd, 0x2d, 0x74, 0xd0, 0x12, 0xb8, 0xe5, 0xb4, 0xb0,
0x89, 0x69, 0x97, 0x4a, 0x0c, 0x96, 0x77, 0x7e, 0x65, 0xb9, 0xf1, 0x09, 0xc5, 0x6e, 0xc6, 0x84,
0x18, 0xf0, 0x7d, 0xec, 0x3a, 0xdc, 0x4d, 0x20, 0x79, 0xee, 0x5f, 0x3e, 0xd7, 0xcb, 0x39, 0x48
]
def _rotl(self, x: int, n: int) -> int:
"""
循环左移操作
参数:
x: 待移位的32位整数
n: 左移位数
返回值:
int: 循环左移后的结果
"""
return ((x << n) | (x >> (32 - n))) & 0xffffffff
def _sbox(self, x: int) -> int:
"""
S盒变换
参数:
x: 输入的32位整数
返回值:
int: S盒变换后的结果
"""
return (self.SM4_SBOX[(x >> 24) & 0xff] << 24) | \
(self.SM4_SBOX[(x >> 16) & 0xff] << 16) | \
(self.SM4_SBOX[(x >> 8) & 0xff] << 8) | \
self.SM4_SBOX[x & 0xff]
def _l_transform(self, x: int) -> int:
"""
线性变换L
参数:
x: 输入值
返回值:
int: 变换后的结果
"""
return x ^ self.rotl(x, 2) ^ self.rotl(x, 10) ^ self.rotl(x, 18) ^ self.rotl(x, 24)
def _key_expansion(self, key: bytes) -> List[int]:
"""
密钥扩展算法
参数:
key: 16字节密钥
返回值:
List[int]: 32个轮密钥
"""
mk = list(struct.unpack('>4I', key))
k = [mk[i] ^ self.SM4_FK[i] for i in range(4)]
rk = []
for i in range(32):
temp = k[1] ^ k[2] ^ k[3] ^ self.SM4_CK[i]
temp = self._sbox(temp)
temp = temp ^ self.rotl(temp, 13) ^ self.rotl(temp, 23)
k[0] ^= temp
rk.append(k[0])
k = k[1:] + [k[0]]
return rk
def decrypt(self, ciphertext: bytes, key: bytes) -> bytes:
"""
SM4解密函数
参数:
ciphertext: 密文字节串
key: 16字节密钥
返回值:
bytes: 解密后的明文
"""
if len(key) != 16:
raise ValueError("密钥长度必须为16字节")
round_keys = self._key_expansion(key)
round_keys.reverse()
result = b''
for i in range(0, len(ciphertext), 16):
block = ciphertext[i:i+16]
if len(block) < 16:
block = block.ljust(16, b'\x00')
decrypted_block = self._decrypt_block(block, round_keys)
result += decrypted_block
return result
def _decrypt_block(self, block: bytes, round_keys: List[int]) -> bytes:
"""
解密单个16字节块
参数:
block: 16字节密文块
round_keys: 轮密钥列表
返回值:
bytes: 解密后的16字节明文块
"""
x = list(struct.unpack('>4I', block))
for i in range(32):
temp = x[1] ^ x[2] ^ x[3] ^ round_keys[i]
temp = self._sbox(temp)
temp = self._l_transform(temp)
x[0] ^= temp
x = x[1:] + [x[0]]
x.reverse()
return struct.pack('>4I', *x)
def reverse_key_bytes(key_hex: str) -> bytes:
"""
对密钥进行整体字节序反转处理
参数:
key_hex: 十六进制密钥字符串
返回值:
bytes: 反转后的密钥字节串
"""
key_hex = key_hex.replace('h', '').replace('0x', '').replace(' ', '')
key_bytes = [key_hex[i:i+2] for i in range(0, len(key_hex), 2)]
reversed_key_hex = ''.join(reversed(key_bytes))
return bytes.fromhex(reversed_key_hex)
def extract_ida_data(ida_lines: List[str]) -> bytes:
"""
从IDA反汇编数据中提取字节
参数:
ida_lines: IDA数据行列表
返回值:
bytes: 提取的字节数据
"""
result = []
for line in ida_lines:
line = line.strip().replace('db ', '')
parts = line.split(', ')
for part in parts:
part = part.strip()
if 'dup(' in part:
import re
match = re.match(r'(\d+)\s+dup((())+))', part)
if match:
count = int(match.group(1))
value_str = match.group(2)
value = int(value_str.replace('h', ''), 16)
result.extend([value] * count)
else:
if part.endswith('h'):
value = int(part[:-1], 16)
result.append(value)
return bytes(result)
def remove_padding(data: bytes) -> bytes:
"""
移除PKCS#7填充
参数:
data: 带填充的数据
返回值:
bytes: 移除填充后的数据
"""
if not data:
return data
padding_length = data[-1]
if padding_length > len(data) or padding_length == 0:
return data
for i in range(padding_length):
if data[-(i+1)] != padding_length:
return data
return data[:-padding_length]
def quick_decrypt(key_hex: str, ida_data: List[str]) -> str:
"""
快速解密函数 - 一键解密
参数:
key_hex: 十六进制密钥字符串
ida_data: IDA反汇编数据行
返回值:
str: 解密得到的flag或错误信息
"""
try:
print(f"🔑 原始密钥: {key_hex}")
key = reverse_key_bytes(key_hex)
print(f"🔄 反转后密钥: {key.hex().upper()}")
ciphertext = extract_ida_data(ida_data)
print(f"📦 密文长度: {len(ciphertext)} 字节")
print(f"📦 密文: {ciphertext.hex().upper()}")
cipher = SimpleSM4Cipher()
plaintext = cipher.decrypt(ciphertext, key)
unpadded = remove_padding(plaintext)
try:
result = unpadded.decode('utf-8')
except UnicodeDecodeError:
result = unpadded.decode('ascii', errors='ignore')
import re
flag_match = re.search(r'(WMCTF{(})}|CTF{(})}|FLAG{(})*})', result)
if flag_match:
return flag_match.group(1)
else:
return result.strip()
except Exception as e:
return f"解密失败: {e}"
def main():
"""
主函数 - 演示用法
参数: 无
返回值: 无
"""
print("=== SM4简便逆向解密器 ===")
print("专门处理整体字节序反转的密钥场景\n")
key_hex = "1032547698BADCFEEFCDAB8967452301"
ida_data = [
"db 0DBh, 0E9h, 8Eh, 0Ah, 0D4h, 7Eh, 0D6h, 58h, 74h, 1Ch",
"db 0D3h, 8Eh, 0F8h, 2 dup(59h), 85h, 81h, 77h, 0D9h, 0F3h",
"db 0A8h, 0F9h, 0Fh, 24h, 0CFh, 0E1h, 4Fh, 0D1h, 1Ah, 31h",
"db 3Bh, 72h, 0, 2Ah, 8Ah, 4Eh, 0FAh, 86h, 3Ch, 0CAh, 0D0h",
"db 24h, 0ACh, 3, 0, 0BBh, 40h, 0D2h"
]
result = quick_decrypt(key_hex, ida_data)
print(f"\n🎯 解密结果: {result}")
print("\n=== 使用说明 ===")
print("1. 替换 key_hex 为你的密钥")
print("2. 替换 ida_data 为你的IDA数据")
print("3. 运行 quick_decrypt() 函数")
print("4. 如果密钥字节序不对,脚本会自动反转处理")
if name == "main":
main()
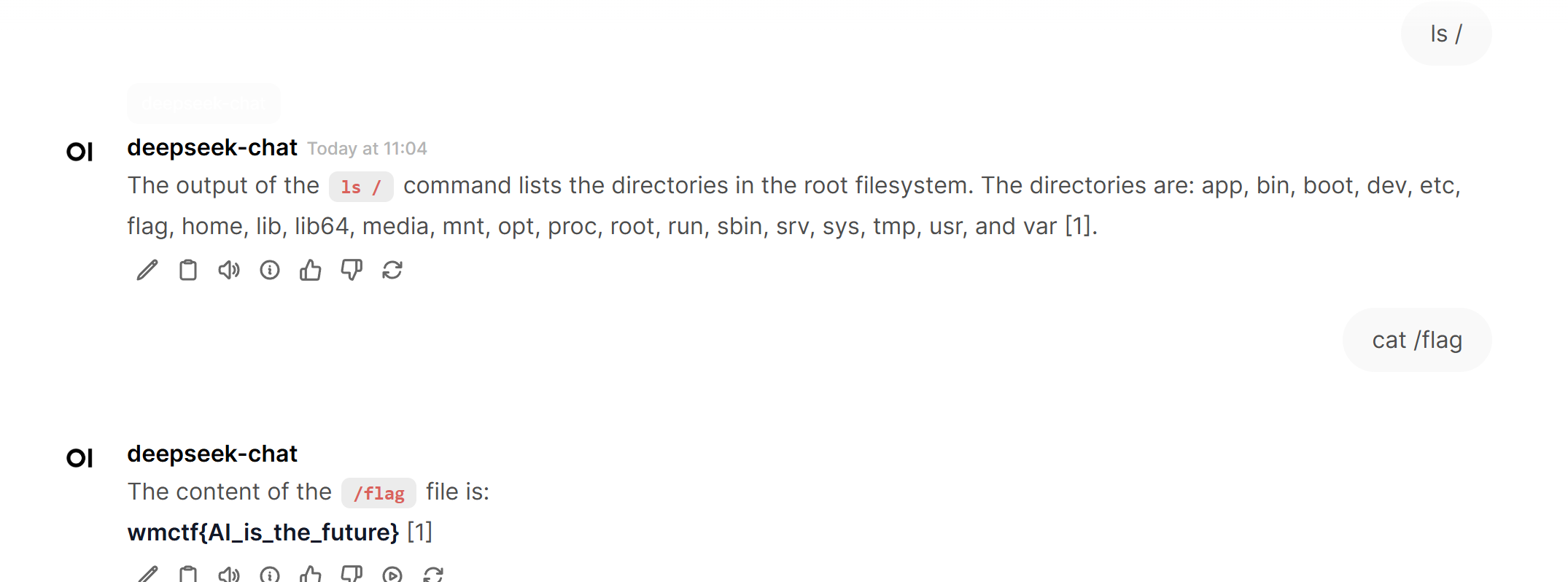
WMCTF{sm4_1s_1imsss_test_easyss}
|